英文原文:How to Write a Git Commit Message
前言:为什么要写好提交记录
如果你随便挑一个 Git 仓库去查看它的提交日志,你可能会发现这些日志通常或多或少都是混乱的。我们可以来看看早些年间我在 Spring 项目中的提交记录:
$ git log --oneline -5 --author cbeams --before "Fri Mar 26 2009"
e5f4b49 Re-adding ConfigurationPostProcessorTests after its brief removal in r814. @Ignore-ing the testCglibClassesAreLoadedJustInTimeForEnhancement() method as it turns out this was one of the culprits in the recent build breakage. The classloader hacking causes subtle downstream effects, breaking unrelated tests. The test method is still useful, but should only be run on a manual basis to ensure CGLIB is not prematurely classloaded, and should not be run as part of the automated build.
2db0f12 fixed two build-breaking issues: + reverted ClassMetadataReadingVisitor to revision 794 + eliminated ConfigurationPostProcessorTests until further investigation determines why it causes downstream tests to fail (such as the seemingly unrelated ClassPathXmlApplicationContextTests)
147709f Tweaks to package-info.java files
22b25e0 Consolidated Util and MutableAnnotationUtils classes into existing AsmUtils
7f96f57 polishing
嗯哼,我们再来跟这个仓库中近期的一些提交记录做个对比:
$ git log --oneline -5 --author pwebb --before "Sat Aug 30 2014"
5ba3db6 Fix failing CompositePropertySourceTests
84564a0 Rework @PropertySource early parsing logic
e142fd1 Add tests for ImportSelector meta-data
887815f Update docbook dependency and generate epub
ac8326d Polish mockito usage
看了这两段提交记录,你更倾向于看到哪个?
前者的记录中,文本的长度和格式都比较随意,而后者的文本长度和格式就都比较统一了。前者的格式纯属自然形成,而后者的格式就不是偶然形成的了。
虽然大部分仓库的日志看起来都更像前者,但 Linux kernel 和 Git 自己 就是两个很好的例外。我们还可以看看 Sprint Boot 项目 或者是由 Tim Pope 管理的任何一个仓库。
👆上面提到的这些仓库的参与者们都很清楚编写一个良好的 Git 记录是用来与其他开发者(也许是他未来的自己)交流和沟通某次修改的上下文内容的最优方式。一次简单的 diff 操作是能告诉你改动了什么,但是只有提交记录才能准确地告诉你为什么要这么改。 Peter Hutterer 很好地指出了这一点:
重建一段代码的上下文是非常费时间的。我们无法完全避免它,所以我们应该尽可能地减少需要重建代码上下文的可能性。提交记录刚好就能帮我们做到这一点,从一个提交记录完全可以看出这个开发者是否能够很好地跟其他人进行协作。
如果你还没有怎么想过一个良好的 Git 提交记录为什么更好,可能是你还没有在类似于git log的这些工具上花太多的时间。这里有个恶性循环:由于提交历史的结构毫无组织并且格式也不一致,所以就没人愿意花时间去利用和管理它。因为这些提交历史从来也没有人会去利用和管理它,所以它的结构就一直毫无组织,格式也就一直这么不一致下去了。
但是一个管理良好的提交日志是一个既漂亮又有用的东西。有了它之后,git blame,revert,rebase,log,shortlog和一些其他的子命令就焕发生机了。这样一来 review 别人提交的代码和 pull request 变得顺理成章了,而且还能独立地进行。如此一来,通过提交记录来搞清楚几个月前乃至几年前都发生了什么不只是变成可能的了,而且还更高效了。
一个项目的长期成功取决于(尤其是)它的可维护性,而一个项目的维护者最有力的工具就是项目的提交日志了。所以花时间去学习如何管理好这些提交日志就显得很很值当,也很有必要了。刚刚开始的时候,大家可能或多或少都会对此有所争论和意见,但是一旦形成了习惯之后,这会让整个项目的参与者都倍感自豪和效率倍增的。
在这篇文章中我只注重于保持一个健康的提交历史所需的最基本要素:如何写好一个独立的提交记录。还有很多其他重要的实践技巧,例如 “commit squashing”(压缩提交记录)等,在这篇文章中我不会展开讨论。也许后续我会单独再写一篇文章来讨论一下。
大多数编程语言中都有一些已经形成的良好约定来保持风格的一致性,例如:命名规则,代码格式等等。当然这种类似的约定有着各种各样不同的版本,但是,我想大部分的开发者都会同意选择其中一种并坚持使用这一种约定,远比大家各自为政搞得混乱不堪要好上千千万万。
一个团队里头大家的代码提交日志的方式方法应该保持一致。为了使得代码库的修改日志变得有用,团队中的所有成员应该就编写提交记录的方式方法达成一个约定,这个约定需要确定这三个要素:
风格,语法、换行、排版、大小写、标点符号,把这些能确定下来的规则都确定下来,别让大家去猜到底要怎么做,尽可能地把规则简单化确定化。最终的结果将是一个风格非常一致的日志,到时候大家不只是愿意去看这些日志了,甚至会时不时地主动去读这些日志了。
内容,提交记录的正文中应该写什么内容呢(如果需要的话)?又有哪些提交记录需要正文呢?
元数据,如何在提交记录中引用 Bug 跟踪号、pull requset 编号等?
幸运的是对于如何编写一个惯用的提交记录已经有了一些既定的约定。事实上,它们中的许多都是可以通过 Git 的命令行功能来达成的。你不需要重新创造任何轮子,只需要遵守以下7条规则,你就可以像一个高手一样编写好你的提交记录了。
一条优秀的 Git 提交记录的 7 条规则
举个例子:
Summarize changes in around 50 characters or less
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of the commit and the rest of the text as the body. The
blank line separating the summary from the body is critical (unless
you omit the body entirely); various tools like `log`, `shortlog`
and `rebase` can get confused if you run the two together.
Explain the problem that this commit is solving. Focus on why you
are making this change as opposed to how (the code explains that).
Are there side effects or other unintuitive consequences of this
change? Here's the place to explain them.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here
If you use an issue tracker, put references to them at the bottom,
like this:
Resolves: #123
See also: #456, #789
1. 使用空行将提交记录的标题和正文分开
从 git commit 命令的手册中我们可以看到:
Though not required, it’s a good idea to begin the commit message with a single short (less than 50 character) line summarizing the change, followed by a blank line and then a more thorough description. The text up to the first blank line in a commit message is treated as the commit title, and that title is used throughout Git. For example, Git-format-patch(1) turns a commit into email, and it uses the title on the Subject line and the rest of the commit in the body.
翻译一下:
虽然这不是必须的,但是我们认为在提交记录的最前面使用50个字符以内的文本来概括一下本次提交的改动是一个很好的主意,然后紧随其后使用一个空行,再接着写更为详细的正文描述。从第一个字符到第一个空行之间的文本内容会被当作提交记录的标题, Git 在各个模块上都是这么处理的。例如: Git-format-patch(1) 会将一个提交记录转换为一封电子邮件,这个时候提交记录的标题就会被当作邮件的标题,而提交记录中其余的内容会被当作邮件的正文。
当然我们需要先说明一点,不是所有的提交记录都一定需要一个标题和正文。有的时候一句话就够了,特别是当某个提交记录就是非常简单的时候,压根儿就不需要再多写什么。例如:
Fix typo in introduction to user guide
就这么一句简洁的描述就够了,如果看到这条提交记录的人想知道修改的究竟是哪个拼写错误,他/她只需要通过 git show 或者 git diff 再或者 git log -p 把修改内容显示出来,简单地扫一眼就能知道具体修改了哪个拼写错误了。
如果你在提交的时候只需要编写这种简单的内容的化,你可以直接在命令行中,简单地在 git commit 命令后面加一个 -m 选项,然后跟上需要填写的提交记录内容即可:
$ git commit -m "Fix typo in introduction to user guide"
不过当一个提交需要解释一下修改的上下文时,你就需要编写提交记录的正文了。例如:
Derezz the master control program
MCP turned out to be evil and had become intent on world domination.
This commit throws Tron's disc into MCP (causing its deresolution)
and turns it back into a chess game.
这种带有正文和标题的提交记录就不太好直接在命令行中通过 -m 选项添加了。这个时候你最好是在一个趁手的文本编辑器中编写你的提交记录。如果你还没有设置好 Git 在命令行中调用的文本编辑器的话,可以参考这篇文章。
总之不论怎样,分开提交记录中的标题和正文对于我们日后再次浏览提交日志是大有裨益的。下面是一个查看提交日志全文的输出:
$ git log
commit 42e769bdf4894310333942ffc5a15151222a87be
Author: Kevin Flynn <[email protected]>
Date: Fri Jan 01 00:00:00 1982 -0200
Derezz the master control program
MCP turned out to be evil and had become intent on world domination.
This commit throws Tron's disc into MCP (causing its deresolution)
and turns it back into a chess game.
现在我们再用 git log --oneline 输出一下,此时 Git 只会输出提交记录中的标题:
$ git log --oneline
42e769 Derezz the master control program
或者我们再来看看 git shortlog,这个命令会将提交记录按照提交者进行分组,为了显示的简洁,Git 也只会输出提交记录的标题。
$ git shortlog
Kevin Flynn (1):
Derezz the master control program
Alan Bradley (1):
Introduce security program "Tron"
Ed Dillinger (3):
Rename chess program to "MCP"
Modify chess program
Upgrade chess program
Walter Gibbs (1):
Introduce protoype chess program
在 Git 中还有很多其他的应用场景也会区分提交记录的标题和正文,但是如果没有标题和正文之间的那个空行的话,这些应用场景就都白扯了。
2. 限制标题字符数在50以内
50 个字符并不是一个硬性的限制,只是一个经验法则罢了。将标题行限制在这个长度首先可以确认它的可读性较好,同时也会强制提交者去主动思考是否可以用更简洁的话来解释究竟发生了什么。
小帖士:如果你发现你很难去概括你的某次提交记录,那么很有可能就是你这次提交了太多的修改了。这个时候你需要尽可能地做到实现提交原子化(这是一篇单独讲提交原子化的文章)。
GitHub 的 UI 交互设计就完全遵守了这些约定。如果你提交的记录中标题的文本长度超过 50 个字符,它就会警告你超出了 50 个字符的限制。
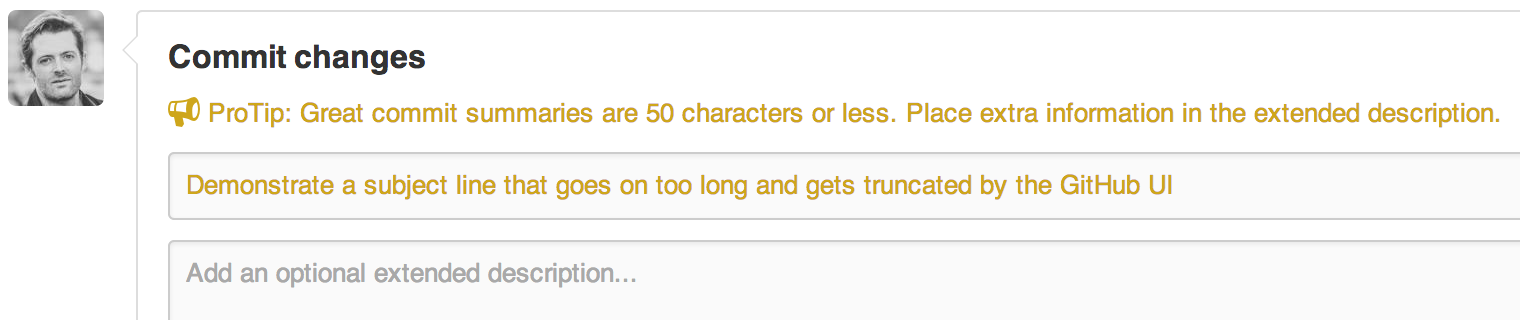 

而且它会将标题中长度超过 72 之后的所有字符截断,并用省略号来代替显示。
 

所以尽可能争取将标题长度控制在 50 以内,实在不行的话也不要超过 72。
3. 标题首字母大写
这一条就是这么简单。确保每个标题的首字母大写就好了。例如,这样:
- Accelerate to 88 miles per hour
而不是这样:
- accelerate to 88 miles per hour
4. 标题行末不使用句号
标题行末的句号是不需要的。另外在标题行中尽量谨慎使用空格,当你想要控制标题长度在 50 以内的话,一个空格都显得尤为珍贵啊。
我们可以这样:
- Open the pod bay doors
但是不要这样:
- Open the pod bay doors.
5. 在标题中使用祈使句
祈使句的意思就是“像发号施令一样地说或写”。例如:
- 打扫房间
- 关门
- 倒垃圾
你现在正在读的这7条规则就是用的祈使句(“限制单行字符长度最大为72”等)。
祈使句听上去感觉有点粗鲁,但这也是我们平时不怎么用到它的原因。但是这正好符合 Git 提交记录标题的需求。其中一个主要的原因就是 Git 自己在我们每次执行一次提交的时候都在使用它。
例如我们使用 git merge 命令进行合并时,自动生成的提交记录是这样的:
Merge branch 'myfeature'
还有 git revert 生成的提交记录是这样的:
Revert "Add the thing with the stuff"
This reverts commit cc87791524aedd593cff5a74532befe7ab69ce9d.
或者当我们在 GitHub 中点击 “Merge” 按钮之后,生成的提交记录是这样的:
Merge pull request #123 from someuser/somebranch
所以当你使用祈使句来编写你的提交记录时,其实你就是在遵循 Git 内建的约定。例如:
- Refactor subsystem X for readability
- Update getting started documentation
- Remove deprecated methods
- Release version 1.0.0
刚刚开始这么写提交记录的时候是感觉有点诡异。因为我们更习惯于使用陈述句来陈述具体的事实。这也是为什么通常的提交记录长得这样:
- Fixed bug with Y
- Changing behavior of X
有的时候提交日志又写得很像是对提交内容的描述:
- More fixes for broken stuff
- Sweet new API methods
为了防止大家搞混而不知道到底应该怎么写,这里有一个屡试不爽的公式可以简单地套用。
一个格式良好的 Git 提交记录的标题应该永远可以直接放在这句话的最后面:
- 如果应用了这个提交,就会 你的提交记录的标题
例如下面这些例子中的标题就是 OK 的:
- 如果应用了这个提交,就会 重构 X 子系统的可读性 (refactor subsystem X for readability)
- 如果应用了这个提交,就会 更新新手入门指南文档 (update getting started documentation)
- 如果应用了这个提交,就会 删除废弃的方法 (remove deprecated methods)
- 如果应用了这个提交,就会 发布1.0.0版本 (release version 1.0.0)
- 如果应用了这个提交,就会 合并某个用户/分支的#123号pull request (merge pull request #123 from user/branch)
而下面这些非祈使句语气的标题就不太好使了:
- 如果应用了这个提交,就会 使用了Y修复了Bug (fixed bug with Y)
- 如果应用了这个提交,就会 修改X的行为 (changing behavior of X) (好吧,我承认这个我不知道要怎么翻译了。)
- 如果应用了这个提交,就会 针对错误更深入的修复 (more fixes for broken stuff)
- 如果应用了这个提交,就会 牛逼的新方法 (sweet new API methods)
记住:我们只是需要在提交记录的标题中使用祈使句。在写提交记录的正文时,就完全可以随意一些了。
6. 限制单行字符长度最大为 72
Git 自己从来都不会主动换行的。当你在写提交日志的时候,你必须注意日志文本的右边距,然后适时地手动换行。
推荐是每行达到 72 个字符就换行,这样的话 Git 在需要控制整行文本内容在 80 字符内的同时,还能有足够的空间来进行格式的缩进。
这个时候我们就需要一个趁手的编辑器。在 Vim 中很容易就能通过配置,让其在我们写 Git 提交记录的时候每到 72 个字符就自动换行。然而通常 IDE 在对提交记录自动换行的支持上都非常的糟糕(虽然 IntelliJ IDEA 在最近的版本中已经对此做了一些的改进)。
7. 在正文中详细解释说明这次提交的改动
这个比特币官方仓库中的提交记录就是一个很好的示范,它很好的解释了此次提交修改了什么以及为什么要做出这个修改:
commit eb0b56b19017ab5c16c745e6da39c53126924ed6
Author: Pieter Wuille <[email protected]>
Date: Fri Aug 1 22:57:55 2014 +0200
Simplify serialize.h's exception handling
Remove the 'state' and 'exceptmask' from serialize.h's stream
implementations, as well as related methods.
As exceptmask always included 'failbit', and setstate was always
called with bits = failbit, all it did was immediately raise an
exception. Get rid of those variables, and replace the setstate
with direct exception throwing (which also removes some dead
code).
As a result, good() is never reached after a failure (there are
only 2 calls, one of which is in tests), and can just be replaced
by !eof().
fail(), clear(n) and exceptions() are just never called. Delete
them.
我们可以对照这次提交的完整 diff来看一下,想象一下作者在这个提交中把本次提交的修改的上下文环境做了如此清楚的说明后,给项目的其他伙伴们以及后续其他的参与者们节省了多少的时间。如果他没有这么做的话,恐怕大家每次都得在这儿浪费时间了。
大多数情况下,我们可以不需要在提交记录中详细地说明我们是怎么做的修改。因为通常代码自己就能将实现的方法表达清楚了(如果这个代码的逻辑确实复杂到没法通过代码自己解释清楚的话,那么这个时候我们就需要在代码里头写注释了)。所以我们在提交记录的正文中,首先要先将为什么要做这次修改的原因说清楚,说清楚在此之前是怎么实现的(以及那么实现有什么问题),然后说明现在是怎么实现的,以及你为什么选择了现在的这种方法来实现的原因。
相信我,后续的维护者都会感谢你的,当然更有可能的是你会感谢你自己。
小帖士
学会使用命令行,忘掉 IDE 吧
鉴于 Git 有太多的子命令可用,我觉得拥抱命令行是明智之选。Git 简直牛逼到炸,当然 IDE 们也很牛逼,只不过它们各自牛逼的地方不太一样。我每天都在使用 IDE(IntelliJ IDEA),而且也曾广泛地使用过其他的 IDE(Eclipse),但是我还从来没有见过哪个 IDE 能将 Git 的功能集成到牛逼如其原生的命令行(一旦你掌握了)。
当然有些 Git 的方法被 IDE 们集成得很棒,例如在删除文件的时候主动调用git rm命令,在我们重命名某个文件的时候,会调用一系列的 Git 命令来实现文件在 Git 仓库中的重命名。但是当你开始使用 IDE 进行 commit, merge, rebase 或者是做些复杂的提交历史分析的时候,IDE 就不行了。
如果你想发挥 Git 的全部潜能,那么命令行是首选。
记住,无论你是在使用 Bash、Zsh 或是 Powershell,都可以通过 Tab 键自动补全脚本来帮助我们更好地记住各种子命令和开关。
好好读读 《Pro Git》 这本书
《Pro Git》 这本书非常棒,而且可以在线免费阅读,好好利用吧,亲!