前文
Dash 是我开始工作有了收入之后,购买的第一款跟开发相关的软件,从 2011 年开始,「这本好字典」就一直在我手边,每每遇到不认识的「字」,打开 Dash 便是我下意识的动作。今天,我们就来聊聊 Dash 这本「好字典」。
我是 2009 年 7 月来到北京,加入超图软件开始了为期不到一年的 SuperMap Objects for Java 的 SDK 开发后,于 2010 年 5 月加入了喜讯无限,开始了自己为期 10 年之久的创业之路。从喜讯无限最初的 Android App 开发到如今的 Flutter App 开发,中间还有为期近 7 年的移动游戏开发经历,期间做过大量的 Unity3D 和少量的 Cocos2dx 开发工作。
在 2011 年,我们当时创业的团队喜讯无限从第二个民房办公地(天居园媒体村)搬到了第三个正经办公地(一路之隔安全大厦)。当时我们那个年轻可爱的创业团队中的几个开发同学大多都是同年毕业的伙伴,其中一位同学,我们总是称他为「正经梁」,他是一位非常非常全栈的折腾党,从硬件到软件,从前端到后端,从数据库到运维,基本上只要他感兴趣的领域,他都非常愿意投入巨大的热情和精力去折腾,验证自己所见所闻并形成自己的一套方法和实践,实属同辈中的佼佼者。
与此同时的我们其他几位伙伴,恰好也都是有好奇心的家伙,只是大家感兴趣的领域可能稍有不同,大家也乐于相互分享。例如「张Tree」同学就非常热衷于体验当时互联网和移动互联网的各种新奇的服务和 App(当时 App 还少得可怜,他们还在用着诺基亚的 E71 呢),在体验之后精选出来他认为不错的服务和 App 分享给我们,对于某些做得有所欠缺或者体验欠佳的友商们,偶尔还会 diss 或心疼一番,「孔雀67」同学就非常痴迷于游戏开发底层框架技术的钻研和图形学,对算法实现有一定的造诣,时不时地给我们丢一两篇很好的文章好某个实现得很优雅的开源框架或引擎的仓库地址。
在那样的环境下,我们一共是 4 位年轻的开发伙伴,「正经梁」负责后端,当时的我们后端使用 PHP 开发(没错,当年的 Facebook 主站核心开发也是基于 PHP 的),他就是那个戏称自己每天站在鄙视链顶端用着「世界上最好的编程语言」跟我们在一起玩。「张Tree」「孔雀67」和「我」,我们三个都是前端程序员,「张Tree」和「孔雀67」由于 C/C++ 的基础不错,还在我们创业之初做过一段时间的塞班(Symbian)应用开发,后面也都转到了 Android 和 iOS 应用开发了,「我」因为从一开始在 Java 编程上有些基础,所以我从 2010 年一开始就在做 Android 开发。
当时的我们四个人,开发环境都大不相同:
「正经梁」=> 自己折腾安装的黑苹果 + VIM
「张Tree」 + 「孔雀67」=> Windows + Visual Studio
「我」=> Ubuntu + Eclipse(ADT)
在我们搬到安全大厦后,趁着大家都在重新布置自己的工位和电脑,「正经梁」同学说要升级一下他的黑苹果到最新的系统,我们还一顿 diss 他,说他穷逼买不起白苹果。然后他笑称「黑苹果一样非常的稳定,没事别瞎搞,GPU 和 CPU 的能力显然性价比更高」,然后建议说我们也可以尝试一下。我随口开了一个玩笑,「你要是帮我装上,我就用,而且能不能双系统?」没想到「正经梁」一口答应了,说「刚好拿我的机器来测试一下最新黑苹果的兼容性,反正你还有 Ubuntu 作为备份」。就这样,我开始使用「黑苹果」,隐约记得当时使用的系统应该是「Mac OS X 10.6 Snow Leopard」,当时做 Android 开发的我主要使用 Eclipse + ADT,在「黑苹果」上除了快捷键需要重新适应一下,其他基本上没有明显的区别。
在开始使用 Mac OS X 之后,慢慢地除了开发之外也有一些其他的需求,很多的时候都会向我的「黑苹果」体验前辈「正经梁」请教一二,而作为一个满怀好奇心和浑身折腾欲的二逼青年「正经梁」总是能给出非常令人满意的答案。Dash 和 1Password 就是在那个时候由「正经梁」墙裂推荐给我的(那会儿我们还不咋使用安利和种草这样的词)。
Dash 和 1Password 这两款软件不愧是「正经梁」的镇机之宝,自打我开始安装这两个软件到的我的电脑上之后,就再也没有离开我的手边。这两款软件,我的首次安装确实都是从「正经梁」同学处拷贝的破解版,都在我使用不到半年之后,主动购买了正版授权,并且在往后的 10 年时间里,每每跟着版本升级再次付费或订阅。
前面叨叨叨地说了这么多,只是想交代一下我是如何接触和开始使用 Dash 的背景,虽然跟本文核心的内容没有那么大的关系,可是跟我自己有很大的关系,在此回忆和说明一下,也还是蛮高兴的。不是老说人会受原生家庭的影响吗?我这也是受到我们这个小小的原生团队的影响才接触到并开始使用 Dash 的。后面咱们还会聊到很多这种「大家毕业后第一份重要的工作会影响我们整个职业生涯」类似的话题,这就算是一个不是那么明显的稍显微妙的案例。
接下来,正文开始。
Dash 能干嘛?
引用一下 Dash 官网的描述
Dash is an API Documentation Browser and Code Snippet Manager. Dash instantly searches offline documentation sets for 200+ APIs, 100+ cheat sheets and more. You can even generate your own docsets or request docsets to be included.
我们简单翻译一下
Dash 是一个 API 文档浏览器和代码片段管理器。 Dash 可以快速搜索包含 200 多个公开的 API 和 100 多个速查表的离线文档集等。你也可以创建自己的文档集或申请官方新增对某些文档集的支持。
从这个描述上来看,这就是一个本地快查开发参考文档的工具,将大量公开的编程语言和开发框架的官方文档聚合到了一个软件中,并且在本地提供了一个快速搜索的功能。
乍看上去,感觉就这么个功能,为啥还要付钱购买呢?而且我记得当年价格应该也不便宜,至少应该是 19.99 美金这样的价格,而且每次大版本升级都需要付费升级,真的值得吗?我的回答是值,非常值,因为每次我基本都是第一时间付费升级,即便近几年我使用 Dash 的频率越来越低(说明自己基本上停止进步和学习新东西了),但是出于一种习惯和支持优秀开发者的优秀作品,确保这样的产品不会消失,我都会用自己的钱来直接投票。
下面我们来展开讲讲,Dash 到底能干嘛?
Dash 的离线文档聚合能力
在 08 年前后,我们发明了一个新词「科学上网」来应对我们的防火墙长城——GFW对某些网络资源的封锁。作为 Android 开发者的我很巧的是,我需要经常查看 Android for Developers 这个归属于 Google 的网站上的开发者资源,其中就包含了 Android 官方的开发文档,那么非常不幸的告诉你,大概率上你是无法非常顺畅地直接访问该网站的。对于当时的我来说,初入 Android 开发门道,很多类和方法都不是那么的了然,时常需要查阅官方文档一窥究竟。虽然那个时候的我也有一些「科学上网」的手段,可以参考 2014 年的我写的文章我是怎么科学上网的,这其中简单概述了多年来我为了能自由访问互联网做过的各种尝试,个中辛酸冷暖自知。
要知道,作为开发人员,无法正常访问一门开发语言(Python语言的官网曾经多年无法正常)和主流开发框架(Android for Developers直到今天依然无法直接访问)的官方文档,对于一个开发者来说,我认为这种难受是令人发指的,而 Dash 将所有在线文档都打包成了离线文档集,我们可以直接通过 Dash 提供的托管地址下载所需要的文档集资源,例如我就一定会下载 JAVA SE + Android + Python 的文档集。随时流畅访问 Android 和 Python 的开发文档,对于我来说,体验无与伦比,当浮一大白。必须给钱!
Dash 的文档本地快速索引能力
早年间众多开发框架和编程语言的官方文档站点虽说基本能做到结构清晰,文档齐全(主流编程语言和框架),但是其搜索能力相对来说都非常的弱,甚至没有。对于我们在初学某门编程语言或者某个新的开发框架时,实际上很多的地图我们都还没有点亮,我们远不知道这地图上都还有些啥,而很多的时候我们又是带着某个问题或者目的而来求索的,然后我们来到了一个官方文档的页面。我们首先看到的是诸如此类的内容:
Install Guide | Download | Get Started | Documention | References
然而这些目录式的陈列,虽然提供了类似于字典般的检索和引导路径,但是对于一个初到此地的陌生人,坦白讲我们可能连北都找不到,假设我想找一下在 Android 中如何调用接口让手机震动,我能怎么快速找到我想找的内容呢?
通常我们都是打开 Google 直接搜索 「android vibration」,当然我发现更多的同学会直接使用百度,搜索内容大致类似「Android 控制手机震动」等等,然后我们可以来看看搜索结果:
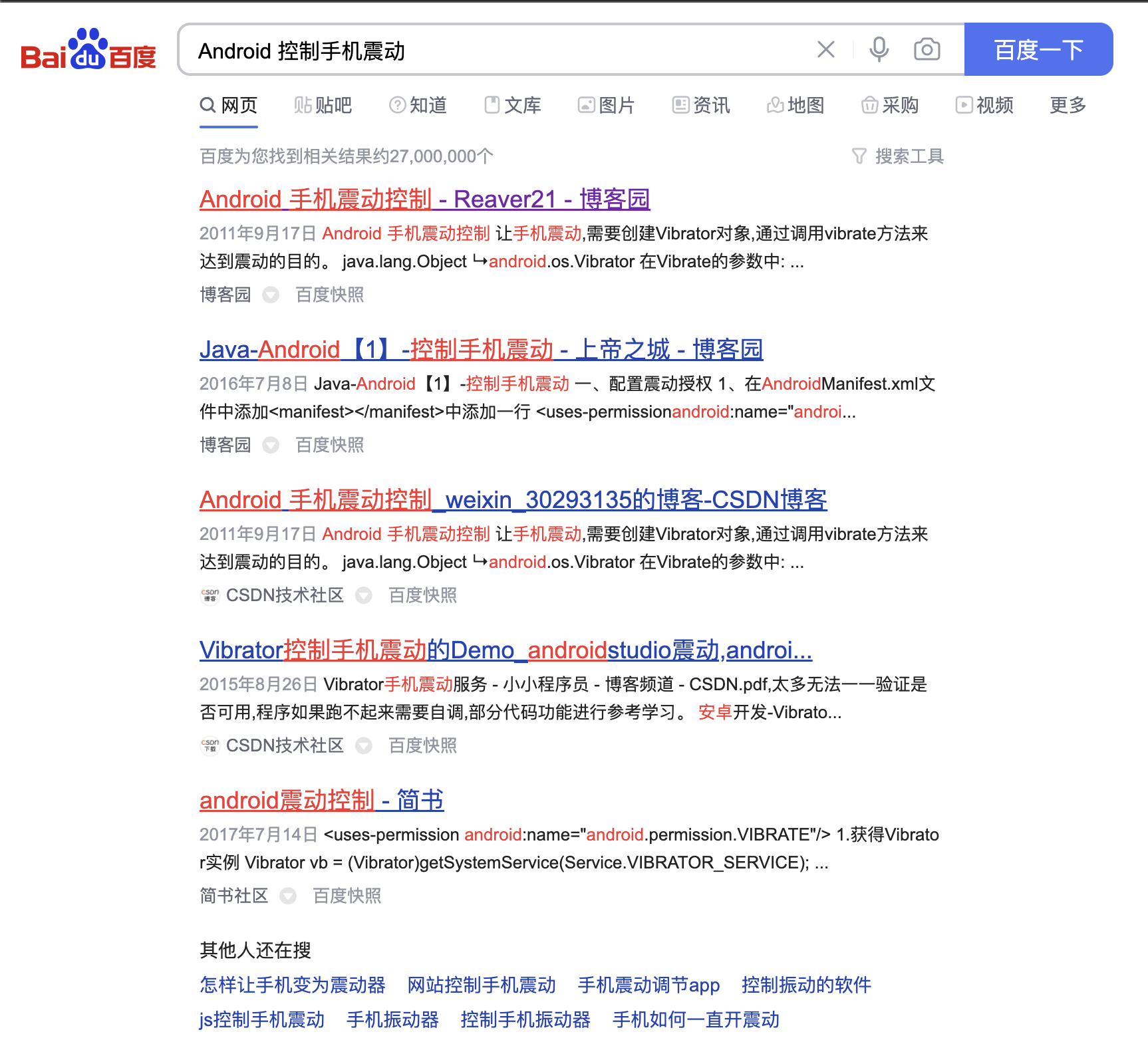
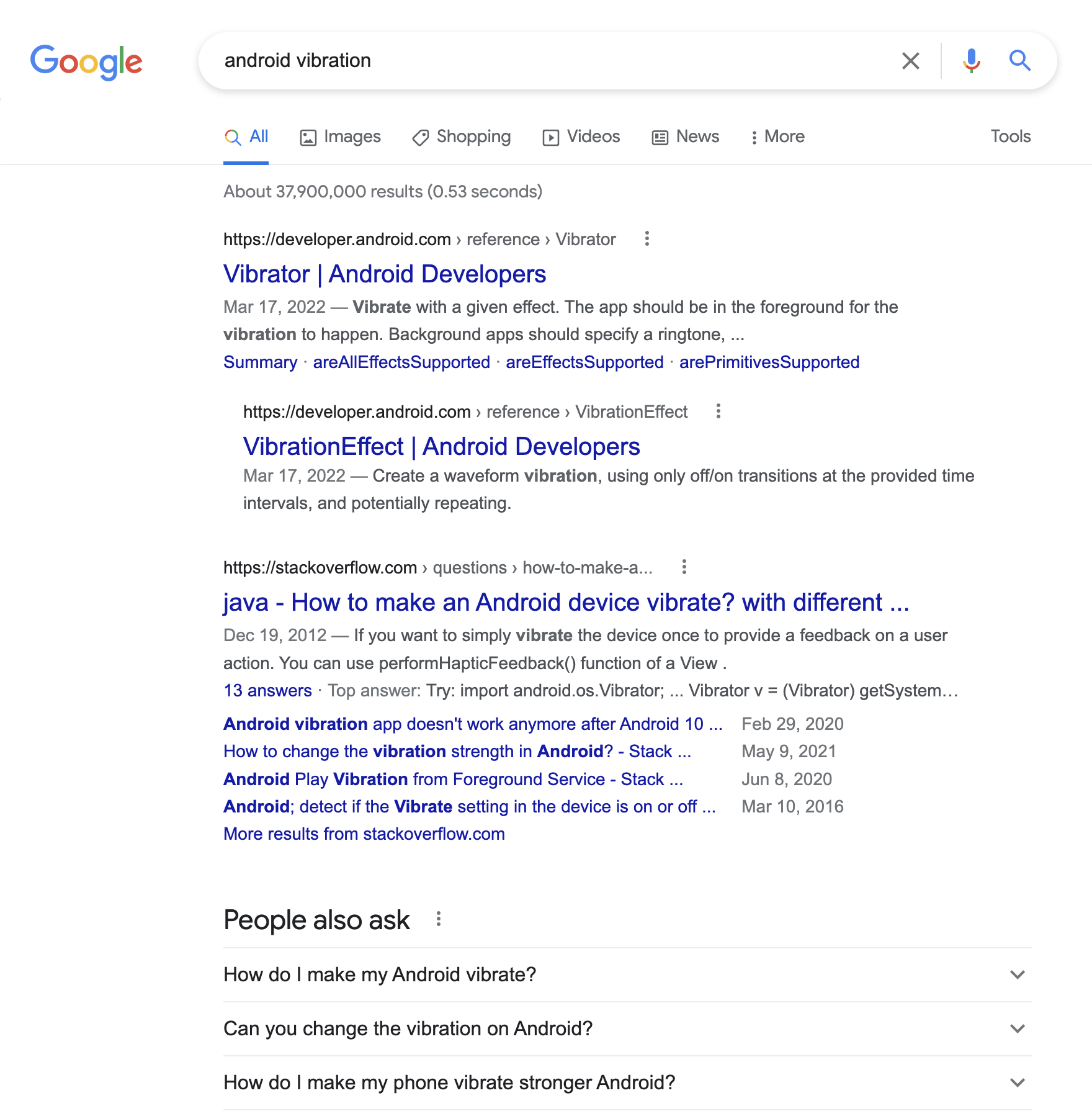
从上图来看,我们发现使用英文搜索引擎 Google 配合英文技术关键字搜索结果会更为符合我们预期一些。然后我们再来看一下在 Dash 中的检索体验是如何的。
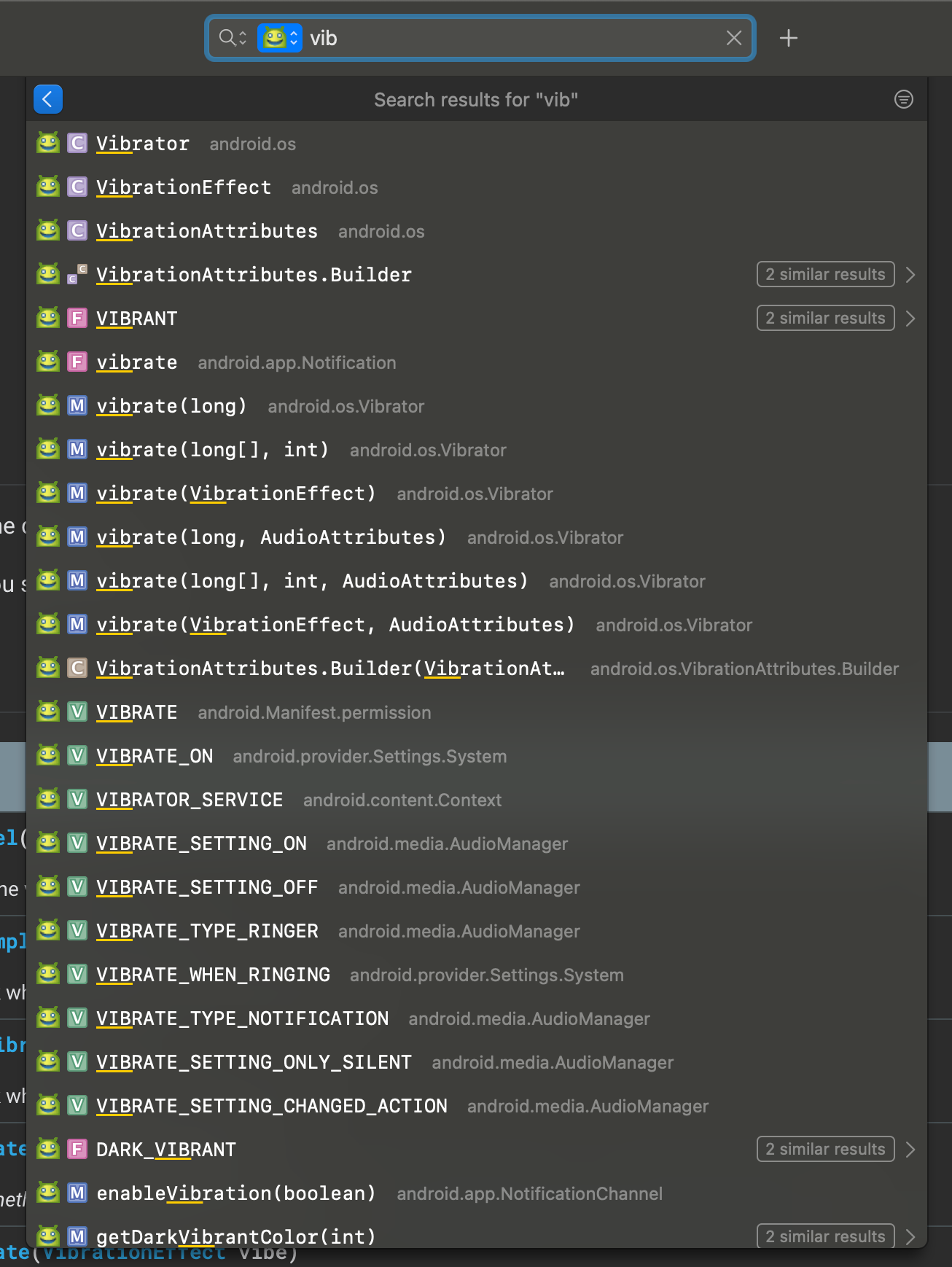
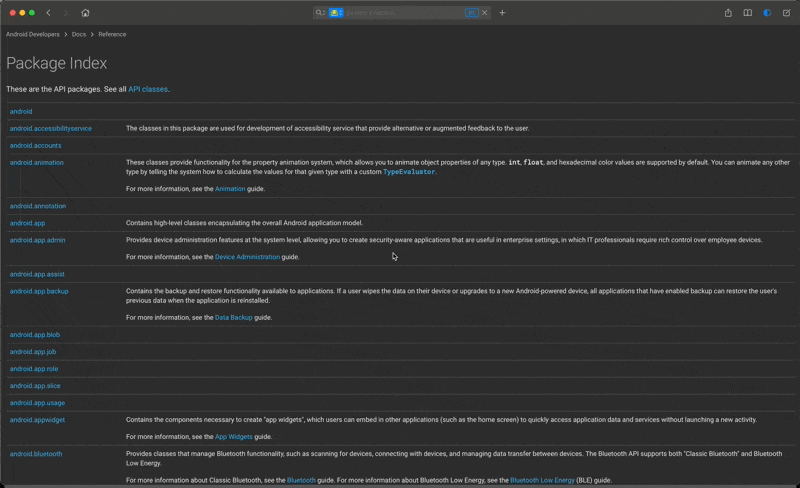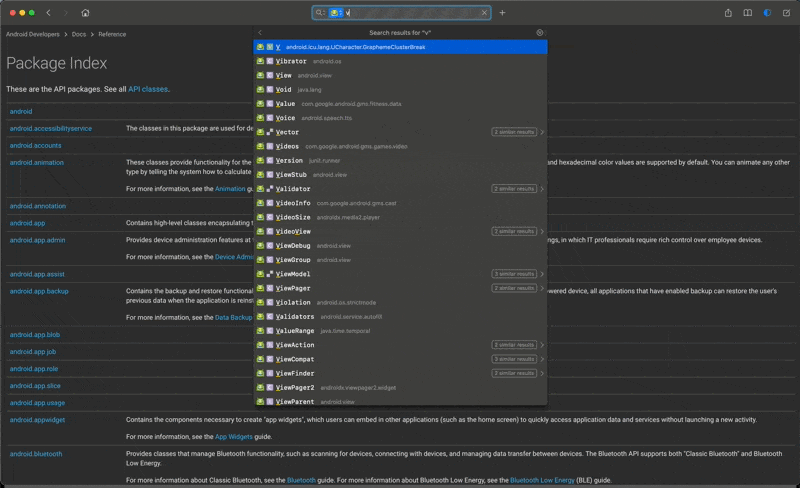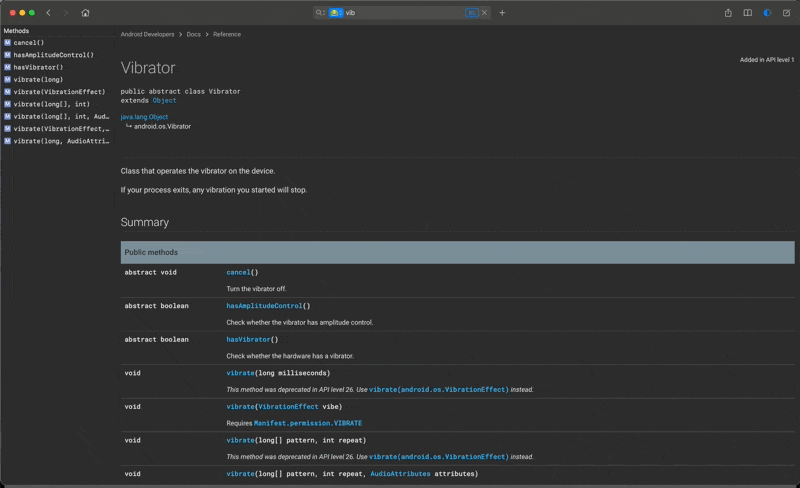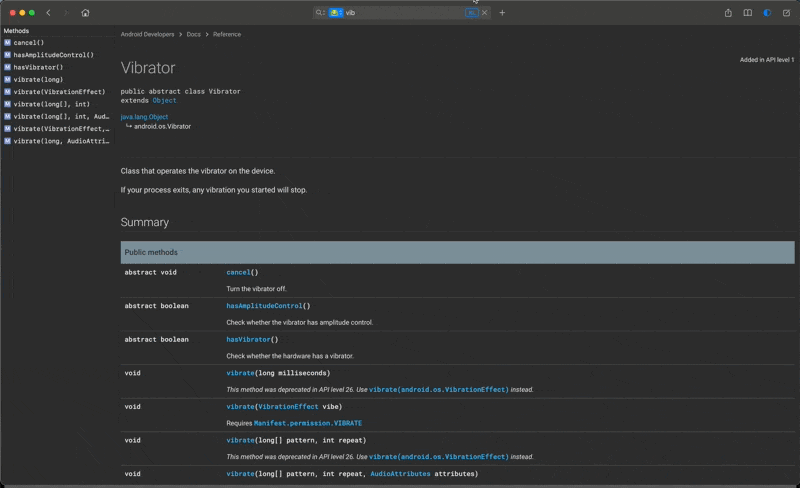
按照我的设定,我只需要输入「and:」这四个关键字先限定我只需要在 Android 的文档集中进行搜索,当我输入「vib」这三个字符后,我就能看到我想要的结果 Vibrator 已经出来了,我一个回车就直接跳转到了 Vibrator 的内容页面了。
虽然这个例子很特殊,但确实不是我刻意挑选的,我就是刚好看到我的手机放在我的手边,收到了一条消息然后手机震动了一下,我就想着是不是可以直接用「手机震动」这个特性来搜索一下。没想到结果也这么的五毛,好像收了钱一样的完全符合我想要表达的。
但是我们理智地来分析一下,实际上很多时候我们作为开发者,遇到一些疑难问题想寻找解决方案的时候,是没有这么明确的关键字可以搜索的,例如「Flutter 中如何监听手机软件盘的打开和关闭?」这样的问题才是我们日常遇到的问题,那么通常我们的解题思路会是啥呢?
我想大部分同学会直接拿着这段关键词在百度搜索框中直接搜索,然后我们也能搜索到很多中文的博客文章,通常文章的来源为「博客园」「CSDN」「简书」「掘金」这么几个地方。我自己的习惯是,先把我自己的问题翻译成英文,然后在 Google 搜索框中搜索,也并没有高级到哪儿去,大家都是换汤不换药,然后通常也能搜到好几篇文章,为首的多是「Stack Overflow」「Medium」,不少的独立博客,偶尔还会有 Youtube 视频结果。
然后大家都会点击搜索结果中的链接,跳转到别人发布的解决方案的文章去查看方案,这个时候如果对方给出的方案中提及了一些关键的类或者方法,咱们好奇心重一些的同学,可能会再拓展延伸阅读一下,通常还是再次回到刚刚打开的搜索引擎页面,再次输入新的关键字,然后重复刚刚我们做的步骤,只是这一次很有可能就会搜索和跳转到我们使用的编程语言或者开发框架的官方文档,如果一次递归还没有到这里,那么递归通常最终结束都是到官方文档这里的。
我们想想看,每次这样在浏览器不同的 Tab 页中频繁的新增和切换,最终达成我们找到解决方案,同时溯源到官方文档的这个流程是否有些过于繁琐了。有了 Dash 之后,基本上我在 Stack Overflow 就可以停止我继续搜索的路径了,通常只需要再配合 Dash 打开具体的编程语言或框架的文档,搜索一下具体的关键词,搭配阅读就能搞清楚我的问题究竟是咋来的要咋解决,以及其中的来龙去脉和基础原理通常八九不离十了。再有兴趣深度了解背后的实现逻辑,我们可能就要转入到源代码级别的阅读了,这里我们就暂时先不展开了。
Dash 提供了一种快速联想的能力
大家可能觉得👆以上咱们谈到的这两个能力确实还不错,对于一个需要快速检索离线 API 文档的开发人员来说,确实是个利器,能给大家提效不少,如果经济实力允许也有购买正版软件的习惯,完全可以买买买。
但是,我更想说的是 Dash 的另一个隐藏的能力才是让我自己最为受益匪浅的,那就是 Dash 的快速检索和反向查找的能力,在事实上提供了一种快速联想的能力,让我能做到举一反三。我还以我刚才随手举的「手机震动」的这个案例来作为切入点,我们可以看看👇下面的这张截图
我们可以看到除了正是我们想找的 Vibrator 可以直接控制手机震动之外,我们还能看到跟系统设置相关的,跟音频管理器相关的,跟系统通知栏相关的,跟权限相关的关键字们。实际上他们都是一些相关联的知识点,只是散落在这个庞大而丰富的 Android 开发文档集中的不同模块里头。通过阅读这些关联的文档,我们不但能直接了解到很多关联的功能和特性,我们更探索到了很多不同的模块,拓宽了我们在 Android 开发这个领域中的全面发展的可能性。
这样类似的例子真的数不胜数,但是关键在于我们要是有心人,是有着好奇心的人,而不是一个快速消费者,来了只点一个蛋挞,吃了就走,完全不看菜单,也不想着自己可能还想吃点其他的,或者先看看了解一下,下回点个鸡翅啥的。而 Dash 就非常好地满足了我自己的好奇心,很多的时候,我就会在使用 Dash 查找 A 的同时,会发散阅读和了解 D 和 S 等等可能并没有那么直接关联的知识点,甚至又回再次回到搜索引擎,最终看了一个 Youtube 视频或者读了一篇其他开发者写的 Medium 长文,花了好几个小时。但是这样提供给我的养料和知识是丰富的,是多维的,更让我能从多方面去了解某一个特性或者知识点。这些知识点终将在我的脑子里形成勾连,最终结网,成为我的能力中的一小块。
Dash 的基本功很扎实
👆以上三点是我自己对 Dash 最为推崇的三点特性,但是其基础功能的靠谱更是前提,下面我们简单挑几个基本功夸一夸啊。
- Dash 的作者做了不少的脏活累活,例如把 .NET Framework, Android, Apple API Reference 等文档做成了 Dash 支持的格式,并且提供了非常快速的离线文档下载速度,请简单回忆一下安装完 Visual Studio 后再安装 MSDN 所需要的时间和那个体验;
- 搜索结果展示的高亮,搜索结果条目的所属模块的展示和相似结果的提醒,都非常好地提供了更多维度的信息,供开发者快速判断和定位自己想要查找的信息;
- Dash 支持的快速关键词匹配特定文档集索引的功能就是一个很不错的创新性的特性;
- 支持第三方文档接入,例如支持第三方文档源:Go Docsets, Java Docsets 等等;
- 与其他开发工具的集成一直都做得不错,我们常用的开发工具和场景基本都覆盖到了,例如我自己偶尔会用到的:IDEA,Visual Studio Code,Terminal,Alfred,PopClip,除了这些还有不少,至少在开发者效率上,作者还是很下功夫和花心思的,哪怕帮咱们省一秒钟,作者也是努力去做了,👍。
结语
拉拉杂杂写了也不少,一个人遇到一款软件,有很多的机缘巧合。我是因为加入了一个非常年轻且好奇心浓厚的一个团队,遇到了一些很可爱的伙伴,然后尝试了这些优秀的软件,对自己造成了一些影响,也许是改变,也许只是更加深了对自我本真的塑造,然后我成为了今天我,不算太好,也不算太坏。
作为一个普通的开发者,我有着比较清楚的自知之明,我也清楚地知道,在真实的互联网开发团队中,很多的开发伙伴们还依然在使用土法制炸弹,虽然做出来的炸弹也能响,也能以此卖得三二两酒钱,但是我想大体上大家还是希望有一些更为不错的工具和方法能让自己做的不那么狼狈,做得不那么辛苦,做得稍微体面一些吧。
希望能提供一丁点帮助,带来多一丢丢启发或思考,大家一起进步,加油。