
关于 Unicode 和字符集,每个程序员都必须掌握的基本内容(别找借口!)
你是否曾好奇过 ”Content-Type“ 这个 tag 究竟是用来干嘛的?就是那个你在编写 HTML 的时候必须设置的 tag,你是不是一直压根都不知道这货是用来干嘛的呢?
你是否也曾收到过你那儿来自保加利亚的朋友发给你的邮件,但是杯具的是邮件标题显示成 “???? ?????? ??? ???” 这样的乱码了呢?
令我失望的远不止于此,我发现非常多的软件开发人员(程序员)对于字符集、编码和 Unicode 这一类的东西毫无了解。几年前,一个 FogBUGZ 的 beta 测试用户曾经问过我们 FogBUGZ 是否可以支持接收日文的邮件。啥,日文?你们还用日文写邮件啊?好意外啊,我怎么知道能不能支持。然后当我开始认真地去研究我们用来解析邮件消息的 MIME 的商业版 ActiveX 控件时,我们发现这货在处理字符集的这件事上彻头彻尾的错了,所以我们必须自己编写代码来避免它做出错误的转换,并且确保解析正确。然后,我又研究了一下另一个商业的类库,好吧,这货的字符处理模块也彻头彻尾的错了。我联系了这个类库的开发者,并跟他沟通了一下这个问题,你猜人家肿么说的,“对此我们无能为力”。就像大部分程序员一般,估计他希望这个问题能随风远去吧。
然而并不会,有木有。当我发现世界上最好的编程语言 PHP 竟然无视字符集的存在,非常牛逼地直接使用 1 个字节(8 位)来保存字符,这使得 PHP 几乎不可能直接用来开发良好的国际化 Web 应用程序(这不是我说的,是 Joel 说的哦)。好吧,也许够用就好了。
所以,在此我要声明一下:如果你是一个 2003 年的程序员,然后你告诉我你对于字符、字符集、编码和 Unicode,那么别让我逮着你,否则我会把你关到核潜艇上去剥 6 个月的洋葱的(尼玛捡肥皂是不是更好)。相信我,我是认真的。
另外,我想说的是:
这并不难。
在这篇文章里,我会尽量将每个程序员在实际工作中都需要掌握的基本内容讲清楚。尼玛那些 “plain text = ascii = characters are 8 bits” 这种鬼画符的东西不止是错了,简直错到姥姥家去了,如果你继续这么写代码的话,那你就跟一个不相信细菌存在的医生差不多了。请你在读完这篇文章之前,别再写任何代码了。
在我开始之前,我需要先说明一点,如果你对于国际化已经很熟悉了话,你会发现整篇文章讨论的内容相对来说会有点过于简单了。我确实只是尝试着设定一个最低标准来进行讨论,以便每个人都能理解到底发生了什么,并且能学会如何编写可以支持除英语之外的语言显示的代码。另外,我需要说明的一点是,字符处理只是软件国际化工作中的很小的一部分,不过今天在这篇文章里头我一次也就只能讲清楚这一个问题。
历史回顾
理解这些东西最简单直接的方法就是按时间顺序来回顾一遍。
你也许觉得我要开始讲一些类似于 EBCDIC 之类的远古时代的字符集了。然而,我就不。EBCDIC 跟你已经没有半毛钱关系了。我们没必要再回到那么远古的时代了。
那么我们回到中古时代吧,当 Unix 刚刚发明出来时,K&R(Brian Kernighan 和 Dennis Ritchie)还在写《The C Programming Language》 这本书的时候,一切都是那么的简单。EBCDIC 就是那个时候出现的。在 EBCDIC 中只考虑到了那些不带音调的英文字母,我们称其为 ASCII,并且使用 32 到 127 之间的整数来代表所有的字符。空格是 32,字母 “A” 是 65,以此类推。这些字母使用 7 位就可以很容易地保存了。不过那个时代的大部分电脑都使用的是 8 位架构,所以不止可以很容易地保存所有的 ASCII 字符,我们还有 1 位富余出来可以用来存别的东西,如果你比较邪恶的话,你完全可以拿这 1 位来偷偷地干坏事:WordStar 这款软件就曾经使用 8 位中的最高位来标记字母是否是一个单词中的最后一个,当然 WordStar 也就只能支持英文文本了。小于 32 的字符被称为不可打印字符,主要用于符咒(开个玩笑罢了)。这些字符是用作控制字符,例如 7 对应的这个字符就是让你的电脑哔哔哔地响,12 这个字符就是让打印机吐出当前正在打印的纸张,接着吸入下一张新的纸张。
 

这一切看上去都还是挺美好的,如果你是一个只说英语的人。
由于这一个字节共 8 位,可以表达的数字是 0 ~ 255,那么就还有可利用的空间,很多人就开始想“对啊,我们可以利用 128 ~ 255 来达成我们自己的一些想法”。可问题的关键是,想到这个点子的人实在是太多了,而且就这 128 ~ 255 之间的数字,他们的想法还各不相同。IBM-PC 的开发人员把这部分设计成了一个提供了部分带有音调适合欧洲语言的字符和一组划线符号的 OEM 字符集,这组划线符号有横杆、竖杠、右边带有虚点的横杠等等,有了这些划线符号,你可以在屏幕上画出非常整齐的方形图案,你现在依然可以在你家的干洗机自带的 8088 微机上看到这些图案呢。事实上一旦当美国之外的人们开始购买 PC,那么各种不同语言的 OEM 字符集纷纷涌现出来,这些字符集们都各自使用这 128 个高位字符来达成自己的设计目的。例如,有些 PC 机上字符编码为 130 的字符是 é,但是在那些以色列出售的机器上,它是希伯来语中的第三个字符(ג),所以当美国人给以色列人发送 résumés 时,在以色列人的电脑上收到之后会显示为 rגsumגs。还有很多类似的例子,例如俄罗斯人,他们对于如何使用这 128 个高位字符编码有着太多太多不同的想法了,所以你压根就没法可靠地通过某种既定的规则来转换俄语的文档。
 

最终这场 OEM 字符集的混战由 ANSI 标准终结了。在 ANSI 标准中,低于 128 编码的字符得到了统一,跟 ASCII 码完全一致,但是对于高于 128 编码的的字符,就有很多种不同的方法来处理了,这主要取决于你住在哪儿。这些不同的高位字符处理系统被称为码点页。例如,以色列 DOS 系统使用了一个名为 862 的码点页,希腊人用的是 737 码点页。这两个系统中,字符编码低于 128 的字符都是一样的,但是高于 128 编码的字符就不同了,所有其他有趣的字母就都放在这儿了。全国的 MS-DOS 版本得有几十个这样的码点页,用来处理从英语到冰岛语,甚至还有部分多语言的码点页用来处理世界语和加利西亚语在同一台电脑上的显示。哇!但是希伯来语和希腊语还是无法在一台电脑上同时显示,除非你自己编写一个程序将所有的字符都按照位图来显示,因为处理希伯来语和希腊语的高位编码的字符所需要的码点页完全不同。
同时在亚洲,这件事情显得尤为严重,因为亚洲语言文字有成千上万的单字,8 位根本无法表达这么多的单字。这个问题通过一个叫做 DBCS(double byte character set) 的系统解决了,在这个系统里头有些单字使用 1 个字节来表示和存储,有些单字使用 2 个字节。这个系统有个问题就是,它可以很容易地实现字符串中往前查找单字,但是几乎没法往后查找。程序员们不应该 s++ 和 s– 这样的操作来往后和往前查找单字,而应该调用类似于 Windows 系统中提供的 AnsiNext 和 AnsiPrev 函数来完成相应的操作,这些函数会自行搞定那些乱七八糟的事情。
但是就是还有那么多的人,他们依然假装 1 个字节就是一个字符,一个字符就是 8 位,而且你也从来不会把一个字符串从这台电脑发送到另一台电脑上,也只会一种语言,这样的话,貌似是没什么问题的。当然,事实上是互联网出现了,字符串在不同电脑之间的传输变得既平常又频繁,这下这些乱七八糟的字符处理系统终于扛不住了。幸运的是我们有了 Unicode。
Unicode
Unicode 很成功地将目前地球上所有的文字书写方式都整合到了一个字符集里头,甚至一些虚构的文字都可以囊括进来,例如克林贡语等等。有些人可能简单地误以为 Unicode 就是一个简单的 16 位的编码,每个字符都是用 16 位来进行存储和表示,那么它就最多能表示 65536 个字符了。实际上这样理解是不对的。这是对于 Unicode 最常见的一种误解,你这么想并不孤独,别在意就好了。
实际上 Unicode 对于字符的管理有一套完全不同的思维方式,你必须理解 Unicode 的思维方式才行。
现在,让我们假设需要将一个字母转换为二进制数据存储到磁盘或内存中:
A -> 0100 0001
在 Unicode 中,一个字母映射一个码点,这个码点是一个理论上的常量值。至于这个码点如何存储到内存或磁盘就完全是另外一回事了。
在 Unicode 中,字母 A 是一个纯抽象的概念,它并不指向任何特定的字符表示形式。抽象的 A 和 B 不是同一个字符,A 和 a 也不是同一个字符,但是 A 和 A 还有 A 指的却是同一个字符。也就是说在 Times New Roman 字体中的 A 和 在 Helvetica 字体中的 A 是同一个字符,但是与同一个字体中的小写的 “a” 却是不同的字符,看上去好像也没啥毛病对吧,但是在有些语言里头这就行不通。例如德语中的 ß 字母究竟是一个独立的字母呢,还是 “ss” 的一个花俏的写法?如果一个字母出现在单词的末尾,它的形状就要发生变形,那么它们要算是不同的字符吗?希伯来语就是这样的,但是阿拉伯语又不是这样的。不过不管怎样,Unicode 组织中那些牛逼的大大们在过去的十年里已经帮我们把这些问题都解决了,天知道他们都经历过了什么样的争辩与妥协(这已经是政治问题了,亲),所以你不需要再去担心这些问题了。他们已经把这些问题都搞定了。
每一个字母表中的抽象的字母都会被 Unicode 组织分配到一个长这样的魔数:U+0639。这个魔数被称为码点。“U+” 代表这个字符采用的是 Unicode 编码并且采用十六进制来表示编码的值。U+0639 对应的是阿拉伯字符中的 ع 。而英文字母的 A 对应的 Unicode 码点是 U+0041。你可以通过 Windows 2000/XP 中自带的 charmap 工具或者访问 Unicode 的官网来查找不同字符的码点或者通过码点进行反向查找。
Unicode 编码所能定义的字符数量是不存在上限的,实际上 Unicode 字符集中定义的字符数量早已经超出 65536 了,所以并非所有的 Unicode 字符能被压缩为两个字节进行存储,但是这听上去有点诡异对吧。
好吧,那么我们来看个字符串:
Hello
在 Unicode 编码中,对应该字符串的 5 个字符的码点值为:
U+0048 U+0065 U+006C U+006C U+006F
至此我们看到的都只是一串码点值,看上去实际上都只是数字而已。我们还没有讨论过如何将这些字符如何存储到内存或者在 Email 中如何显示它们。
编码
想解释上面的两个问题,就需要涉及到编码了。
最早的 Unicode 编码试图将所有的字符都编码为两个字节来存储,那么好的,我们只需要将这些数字编码为两个字节,然后按顺序排好。那么 Hello 就成这样了:
00 48 00 65 00 6C 00 6C 00 6F
就这样吗?等等,我们看看这样行吗?
48 00 65 00 6C 00 6C 00 6F 00
从技术上来说,这两种编码方式都是可以的,事实上早期的 Unicode 编码实现者们就希望能以大端字节序或者小端字节序的方式来存储他们的 Unicode 码点,无论他们的电脑的 CPU 是快还是慢,现在是白天还是晚上,反正现在就是有了两种存储 Unicode 码点的方式了。所以人们就必须在处理 Unicode 字符串之前,遵守一个奇怪的约定,那就是在每一个 Unicode 字符串的最前面加上 FE FF 这两个字节(这被称为 Unicode 字节顺序标记,也被戏称为 BOM,炸弹的谐音)用来标记这个 Unicode 字符串的编码字节序是大端字节序,如果使用小端字节序进行编码存储的话,就在 Unicode 字符串编码的最前面加上 FF FE 两个字节,这样一来解析该 Unicode 字符串的人,在读取整个字符串编码的最前面两个字节就能判断当前的 Unicode 字符串究竟是采用大端字节序进行编码存储还是使用的小端字节序。但是,你懂的,真实的情况是,并非所有的 Unicode 字符串都会在其最头部加入所谓的 BOM 噢。
这看上去都挺好的,可是过了没多久,就有一帮程序猿开始有意见了。他们说:“靠,你们看看这些 0 们,你们有什么想法没有!”。因为他们是美国人,而且他们看到的也大都是英文,所以他们几乎从来都不回用到高于 U+00FF 的码点。另外他们还是加州的自由主义嬉皮士,他们很想节约一点存储空间(呵呵)。如果他们是德州人,他们就压根不会在意这多出来一倍字节数。但是加州的这帮弱鸡们就是无法忍受要把存储字符串的的空间給增大一倍,并且他们已经有了那么多的该死的文档已经是使用 ANSI 和 DBCS 字符集进行编码和存储的,尼玛谁愿意再一一地去給这些文档做格式转换啊?光是出于这个原因,很多人在很长的一段时间里头都选择无视 Unicode 的存在,与此同时,事情变得越来越糟了。
于是机智的 UTF-8 登场了。UTF-8 是另一个用来编码存储 Unicode 字符码点的编码方式,使用 8 个比特来存储码点魔数种的每一个数字。在 UTF-8 中,码点从 0 到 127 的字符都是使用一个字节来进行存储。只有码点值为 128 以及更高的字符才会使用 2 个或者 3 个字节进行存储,最多的需要使用 6 个字节。
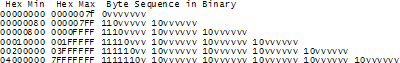 

这个方案有个巧妙的附带效果,那就是对于英文来说,在 UTF-8 和 ASCII 中的编码几乎是一模一样的,所以美国人根本都意识不到有任何问题。只有世界上其他地区的人才需要去跳过这些坑。还以这个 Hello 为例,它的 Unicode 码点是 U+0048 U+0065 U+006C U+006C U+006F,在 UTF-8 编码中将会以 48 65 6C 6C 6F 的形式来存储。看,这就跟使用 ASCII 和 ANSI 编码进行存储一毛一样了对伐。好了,现在如果你执意要使用带有音调的字母或者是希腊字母和克林贡字母的话,那么你就需要使用多个字节来保存一个字母的码点了,但是美国人压根儿都意识不到。(UTF-8 还有一个优良的特性,就是那些无知的使用一个值为 0 的字节来作为字符串终止符的老旧字符串处理代码不会错误地把字符串給截断了)
目前为止,我已经告诉了你有三种 Unicode 字符的编码方式。最传统的做法是将所有的字符编码保存到两个字节中,这种编码方法被称为 UCS-2(因为存储在两个字节里头)或者 UTF-16(因为使用了 16 个比特),而且你需要根据字符串的 BOM 来判断其存储采用的是大端字节序还是小端字节序。更为普遍被采用的就是新的 UTF-8 编码标准了,使用 UTF-8 编码有个好处,就是对于那种无脑的只能处理 ASCII 字符陈年老程序或者碰巧你只需要处理英文文本的话,你几乎不用做任何调整就可以正常使用了。
当然实际上还有很多种不同的 Unicode 字符编码方式。例如 UTF-7 就是一种跟 UTF-8 非常相似的编码方式,但是它会确保一个字节中的 8 个比特中最高位的值永远为 0,所以如果你必须通过某种认为只需要使用 7 个比特来进行字符编码就够了的政府-警察的电子邮件系统来发送 Unicode 字符的话,UTF-7 就能将 Unicode 字符压缩到 7 位并进行编码和存储,而不至于丢失字符串中的任何内容。还有 UCS-4,它将每个 Unicode 字符的码点编码为 4 个字节进行存储,它的优势是所有的字符都是使用相同的字节数进行存储,不过,这样的话,即便是德州人估计都不太乐意浪费这么多的内存空间了。
现在你在想的应该是,理论上来讲,所有这些通过 Unicode 码点来表示的字符,应该也能通过原来的老的编码方式来进行编码才对啊。例如,你可以讲 Hello(U+0048 U+0065 U+006C U+006C U+006F)的 Unicode 字符串通过 ASCII 编码的方式进行编码,也可以通过老的 OEM Greek,甚至是 Hebrew ANSI 编码方式,乃至前面我们提到的几百种编码方式。但是使用这些老的编码方式对 Unicode 字符进行编码都会有同一个问题:那就是有些字符是无法正常显示的。如果在这个编码方式中找不到一个跟 Unicode 字符的码点对应的字符来显示,你通常都只能看到一个问号 ?,或者更好一些的就是一个带着黑色的块中有个问号 �。
有好几百种这种过时的编码系统,只能正确地存储一小部分的 Unicode 字符码点,然后将其他的字符都存储的存储为问号 ?了。例如一些非常常用的英文文本编码方式 Windows-1252(Windows 9x 中内置的西欧语言的标准编码方式)和 ISO-8859-1 也叫做 Latin-1(也适用于所有西欧语言),都没法正确地存储俄文字符或者希伯来语字符,而只会把这些字符变成一串串的问号 ?。而 UTF 7,8,16 和 32 就都能很好地将任何码点的字符进行正确的编码和存储。
关于编码的一个最重要的事实
如果你已经完全忘掉了我刚刚吧啦吧啦讲了的一大堆东西,那么就记住一个非常重要的事情,那就是“如果不知道一个字符串使用的是什么编码,那么你就完全不知道它会是个什么鬼”。你再也不能像鸵鸟一般把头埋到沙子里头,然后假装所有的纯文本都是使用 ASCII 编码的。
根本就没有什么纯文本这样的东西。
如果你有一个字符串,不论它是在内存里,在文件中,还是在一封电子邮件里头,你都需要知道它的编码方式,否则你压根就没法正确地解析它,然后再正确地显示给你的用户。
几乎所有类似“我的网站看起来尼玛彻底乱码了啊”以及“她没法查看我发的带有音调字母的电子邮件”这种傻逼问题,通常都是因为某个无知(naive)的程序猿压根儿都没理解一个很简单的道理,那就是如果你不告诉我你的字符串使用的是 UTF-8 或者 ASCII 还是 ISO-8859-1(Latin 1),又或是 Windows 1252(西欧语言)编码,你压根儿就没法正常地显示这些字符,甚至都没法判断字符串在那儿结束的。高于 127 的码点字符的编码方式有好几百种,这就彻底歇菜了。
那么我们如何将字符串使用的编码信息保存起来呢?当然,这也都有标准的方法来实现。例如在电子邮件中,你就需要在邮件内容的头部加入一段这种格式的文本来说明这封电子邮件正文使用的编码方式:
Content-Type: text/plain; charset=”UTF-8″
对于网页来讲,最开始的想法是这样的,Web 服务器在每次返回网页内容的同时会返回一个类似的 Content-Type 的 HTTP 的头信息,注意不是在网页 HTML 文件中,而是在服务器返回 HTML 文件之前通过一个 HTTP 的响应头返回的。
不过这样就带了一些问题。假设你有一个庞大的 Web 服务器,这个服务器上部署了很多的网站,而且这些网站的网页是由很多使用不同语言的人创建的,而他们都直接使用微软的 FrontPage 编写网页,然后直接将 FrontPage 生成的网页文件拷贝到服务器上。服务器没法真正地确定每个网页文件实际上使用的编码方式的,所以它就没法正确地发送 Content-Type 的 HTTP 头了。
如果你能使用某种特殊的 tag 将 HTML 文件的 Content-Type 在网页文件内进行正确地声明,那么也是挺方便的。但是这就让那些纯粹主义者们就疯了,在你知道一个 HTML 文件的编码之前,你要怎么读取这个 HTML 文件来解析它内部的内容呢?(听起来有点鸡生蛋,蛋生鸡的意思噢)不过幸运的是,几乎所有常用的编码对于码点值 32 到 127 之间的字符处理都是一样的,所以你总是可以直接解析 HTML 文件中的关于编码的 tag 的内容,而不需要关注可能出现的乱码的字符,通常 HTML 文件中关于编码的 tag 的内容如下:
<html>
<head>
<meta http-equiv=“Content-Type” content=“text/html; charset=utf-8”>
我们需要注意的是这个 meta tag 必须是 <head> 标签中的第一个子节点,因为浏览器在读取到这个 meta tag 之后就会马上停止继续解析当前的网页内容了,而是使用 meta tag 中声明的编码重新开始解析当前网页的内容。
那么如果浏览器没有从 HTML 文件和 Web 服务器返回的 HTTP 头中读取到任何指定当前网页的 Content-Type 的信息,浏览器会怎么解析当前网页呢? IE 浏览器实际上会做一些很有意思的事情:它会基于不同的字节在不同语言中的常用编码和出现频率,尝试着去猜测当前网页使用的语言和编码方式。由于不同的老的 8 位码点页编码系统总是尝试着将其国家或地区语言中特殊字符映射到 128 到 255 之间的不同点位,而每种语言中的字符实际上是有其统计上的特征的,所以 IE 浏览器的这个自动判断当前网页使用的语言和编码方式偶尔还是能奏效的。乍看上去非常诡异,但是由于总是有些无知的网页开发者压根儿就不知道需要在他们编写的网页的头部声明网页的 Content-Type 以便浏览器能正确地展示他编写的网页。直到有一天,他们编写了一个不符合他们母语字符分布规律的网页,而 IE 浏览器最终会把这个网页当成韩文来进行渲染展示,坦率地讲我认为波斯特尔法则(Postel’s Law)—— “严于律己,宽于待人”(哈哈,这个翻译有点诡异,实际上的意思是,对于自己创建和发送的内容要尽量严格要求,减少出错的可能,而对于我们接收的内容要尽可能的宽容,并考虑容错)并不是一个好的工程准则。不管怎么说,这个网站可怜的读者们面对这原本应该显示为保加利亚语的网页被显示为韩语(还不确定是北朝鲜语或者是南朝鲜语),他又能做什么呢?他可以使用 IE 浏览器中菜单栏里头的视图(View)|编码(Encoding)选项来尝试使用不同的编码方式(大概有个几十种东欧的语言吧)来显示当前网页,直到他最终试出了当前网页使用的语言和编码。当然前提是他得知道这么操作才行,然而实际上绝大部分人根本就知道怎么调整浏览器渲染和显示网页时使用的编码。
在我们公司发布的最新版本的网站管理软件 CityDesk 中,我们决定在软件内部实现中都采用 UCS-2 编码,这也是 Visual Basic、COM 和 Windows NT/2000/XP 底层使用的字符串编码方式。在 C++ 中,我们将所有的字符串都声明为 wchar_t(宽字符) 类型,而不再使用 char 类型,使用 wcs 方法,而不再使用 str 方法(同理我们会使用 wcscat 和 wcslen 替换 strcat 和 strlen 方法)。在 C 语言中,你只需要在字符串的前面加上一个大写的 L,例如 L“Hello” 就可以创建一个字面上的 UCS-2 字符串了。
在 CityDesk 发布网页时,它会将所有的网页都转化为 UTF-8 编码,多年以前各大浏览器对 UTF-8 编码的支持就已经非常好了。这也是为什么 Joel on Software 这个网站拥有 29 种语言的版本,但是我从来没有听说过任何一位读者反馈说他没法正常地浏览这个网站上的内容。
这边文章写得实在是太长了,但是我依然无法在这一篇文章里涵盖字符编码和 Unicode 的所有内容,但是我依然希望当你读完这篇文章,再回去编程的时候,能不再盲信什么水蛭或咒语可以治病,而是学会如何正确地使用抗生素,这是是我想留给你的一个小任务。