2010年的7月10日,我们发布了「黄金矿工喜讯特别版」,当时我写了一篇文章,链接在这里《黄金矿工喜讯特别版》发布了。
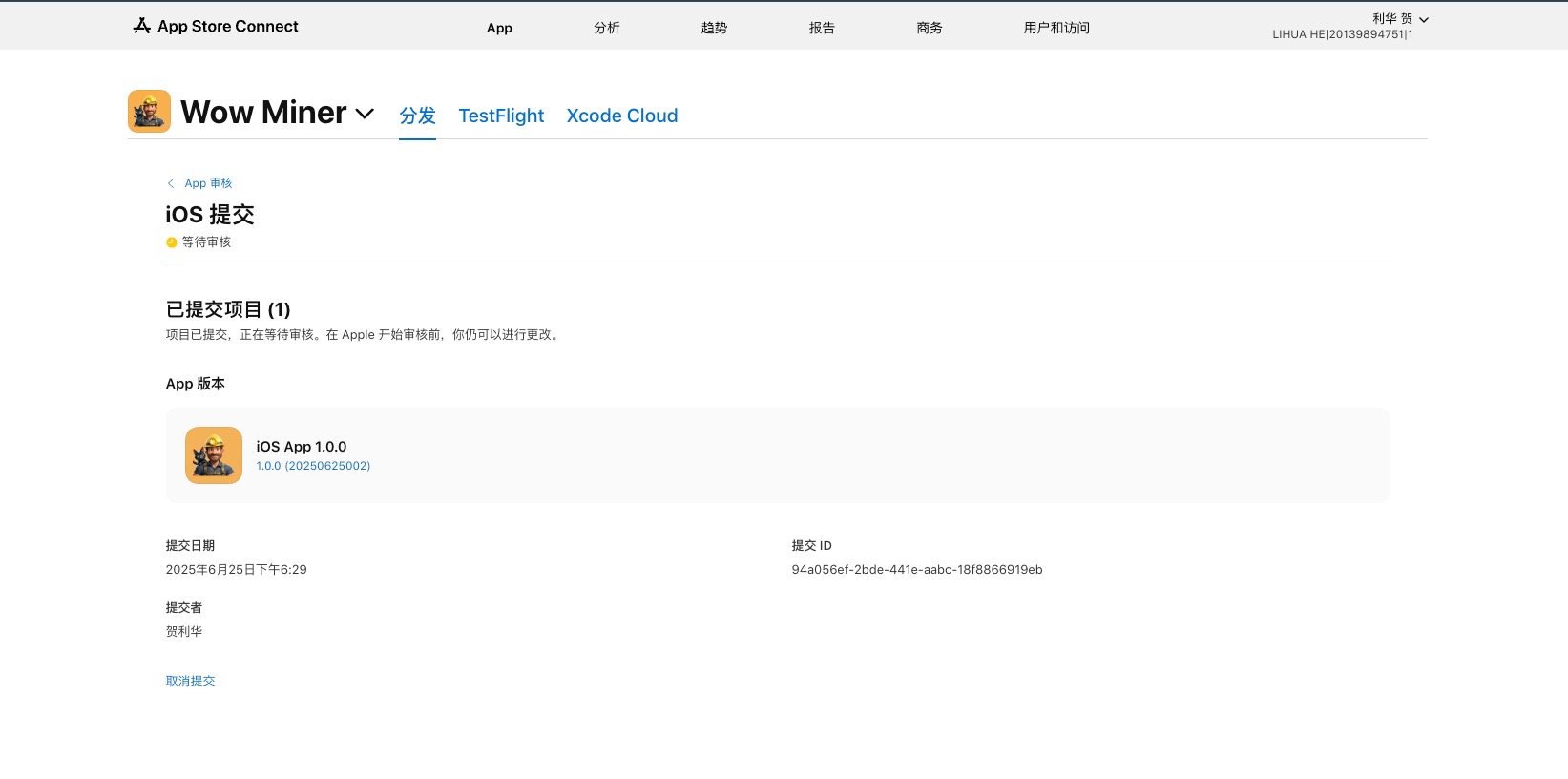
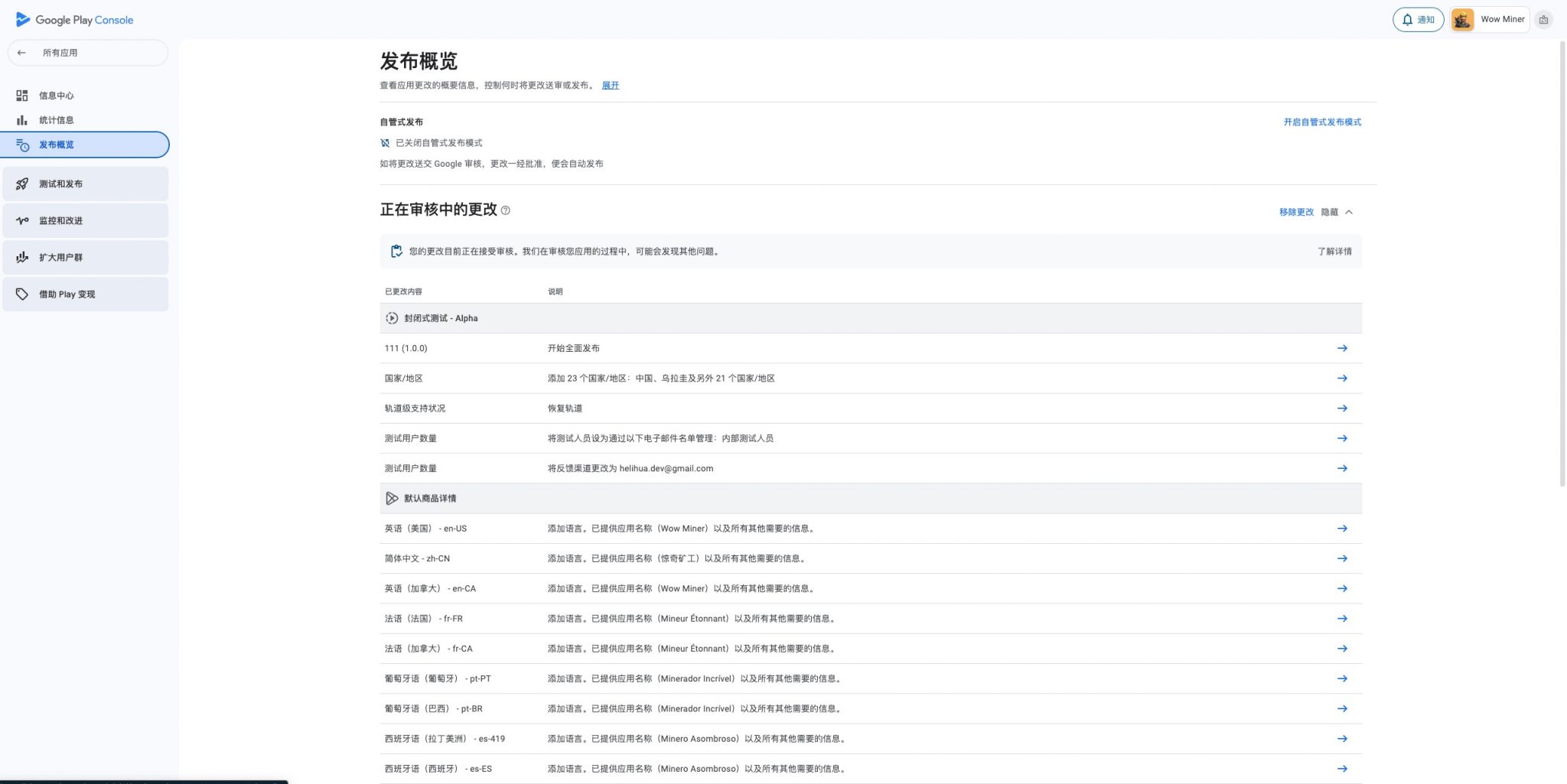
时隔15年,今天是2025年的6月25日,今天我提交了名为「Wow Miner」的「黄金矿工喜讯特别版」的重制版,说它是重制版,主要原因有两个:
- 核心玩法并没有变,还是那几个核心元素和NPC类型,甚至还减少了一个抓斗切换的功能,NPC也少了一种被击晕的状态;
- 核心视觉没有变,我遍寻互联网找到了当年我们发布的版本的APK文件,逆向导出了原来资源,找到了此前的播客文章,把文章中的截图和逆向出来的资源图给到了当年我们的主美老哥哥,老哥哥凭着截图和脑子里的印象,参考原来的超低分辨率的资源(当时游戏的 NPC 尺寸是64×64像素)重新一笔一笔还原了一套新的资源(老的APK在新的手机上因为屏幕尺寸的问题基本上已经完全无法适配并正常体验了);
本次重制基本上完全复原了原有的玩法,但是关卡无法复用,当前的关卡都是我们老大用 XML 直接手写的,他跟我约定好所有 XML 标签的意义,我在代码中解析的时候按照文档中定义好的规则来编写代码适配,在我入职后的两个月里从 0 到 1 自己一个人在我的 HTC Hero 上完成开发、调试和测试,从完全不知道状态机是什么意思到把游戏发布到国内安卓论坛(那会儿还没有像样的应用市场),我就这么自己一点点把这个硬骨头啃下来了。
现在想想,当年我从超图离职跟着我最好的朋友孔雀67去到龙德紫金的小办公室面试,记得我们老大应该是当场就录用了我,但是我当时说了一句我到现在还记得很清楚的话「只要老大你不做游戏,我就跟着你干」(那会儿我对做游戏是很排斥的,我也说不上为啥,我们宿舍四个哥们,一个毕业去了金山,就是我最好的朋友孔雀67,另一个去了Gameloft北京,当时叫智乐,还有一个跟我一样在超图,但是没多久也去了金山找孔雀67去了,那个时候的我只想做互联网相关的业务,应该是那会儿看互联网造富新闻看多了)。殊不知我加入喜讯后的第一个项目,竟然就是手搓一个黄金矿工,那会儿可没有什么 Unity 和 Unreal 能用啊,只能纯靠着 Android 最早期版本中 SurfaceView 中提供的那么几个极其有限的绘图相关的方法来实现,还得考虑当时 Android 系统中的对于进程内存的限制,应对时不时的 OOM 崩溃问题。
时隔15年,加入喜讯后先是做了2年的移动互联网社区和工具,然后又莫名其妙的在游戏行业摸爬滚打了7年,再是进入了直播社交行业干了6年,在已经不写代码快3年之际,重新捡起来了已经快忘得差不多了的Unity 做起了 2D 游戏,折腾了一段时间,总算是有了一个结果,今天双端都测试完毕,提交 Play Store 和 App Store 了。当然现在的游戏开发,甚至关卡设计,Cursor 和 Jetbrains AI 都能帮上很大的忙,甚至游戏工作室的官网都是 AI Agent 帮着完成设计、开发和部署的。ChatGPT 和 Claude 都是得力干将,委实让我们这些写代码的轻松了不少。
附上两个应用商店的提审截图,留个纪念,当然还有我的游戏工作室官网地址:Wow! Play Studio