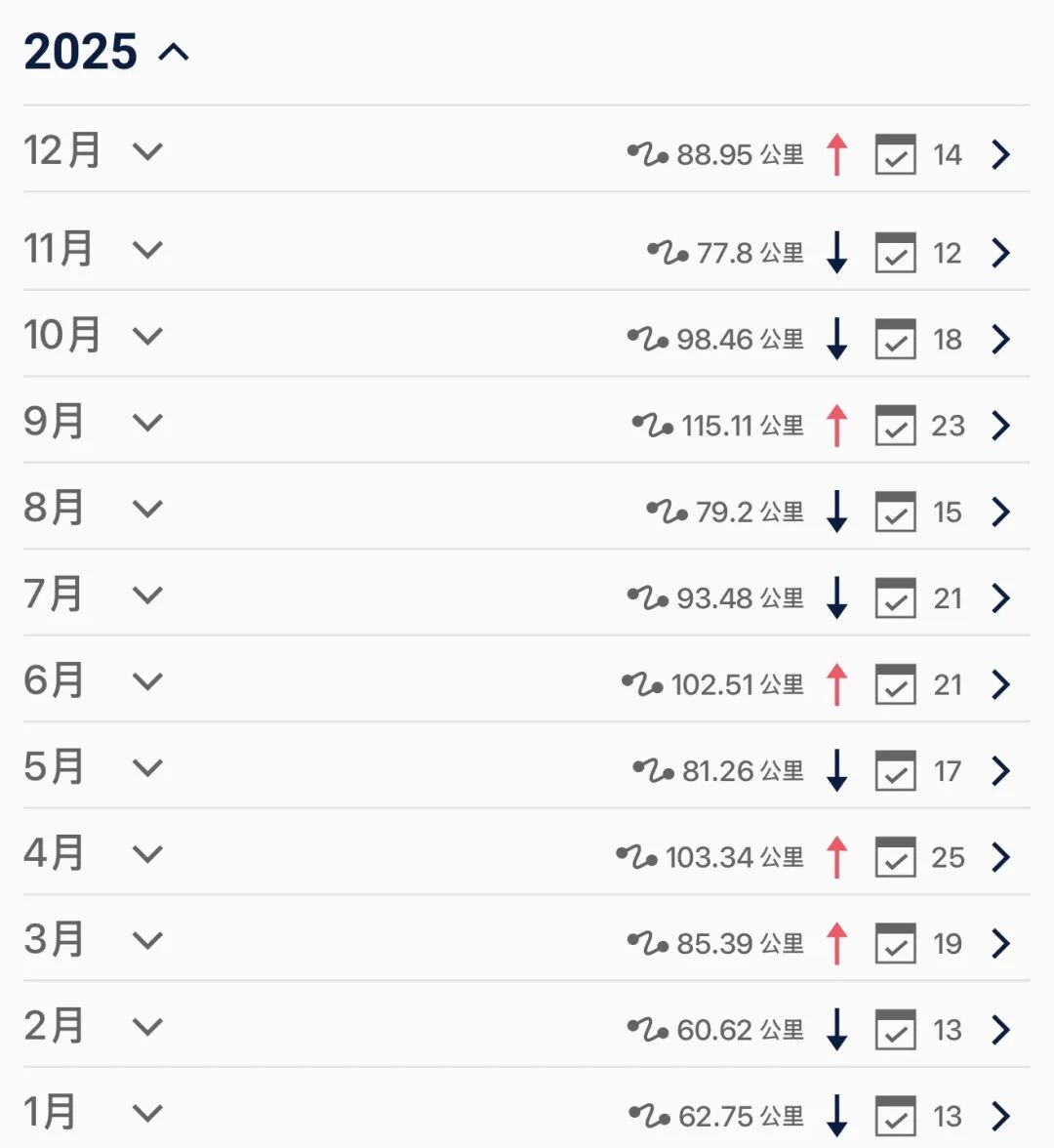
开篇声明:本篇不拉不踩任何AI工具和厂商,仅从我个人实际应用体验出发,而本人的实际应用多有局限,且场景偏颇,本文所有的观点都仅供参考,核心是作者本人想要留作记录,同时保持练习写字输出而已,大家读完笑一笑即可。
事情是这样的,Google Gemini 3 Pro模型发布后,业界各种评测文章热烈追捧之下,我也未能免俗,也主动尝试了一把,在试用Antigravity一周帮忙做了几个小的独立工程(改改官网静态页面,一句话做个小App)之后,觉得这货简直就是另一个AI菩萨(免费,可用,速度快,还有一个赛博菩萨是Cloudflare,此处不细说),但是在我想要尝试高密度使用的时候,时不时地就出现了刚提交提示词便返回错误的问题,实在太影响体验了,便当场升级为Gemini Pro用户了,升级完成后再次出现错误的概率就非常低了,最近大概一天能遇到3~5回(在我密集使用的情况下),所以花钱就是能变强😂。
在把此前主要编码的工作从Cursor切换到了Antigravity一周后,我先把我刚刚恢复订阅的Cursor再次取消了订阅,回过头去看了一眼Curosr的订阅记录,发现实际上我一直也没有停掉对Cursor的付费使用,中间短暂地离开后在其发布Curosr 2.0后又马上回去了(那段时间我应该是重度使用了Claude Code,还订阅了其Max套餐)。
这次再次主动取消 Cursor Pro 的订阅原因有二:
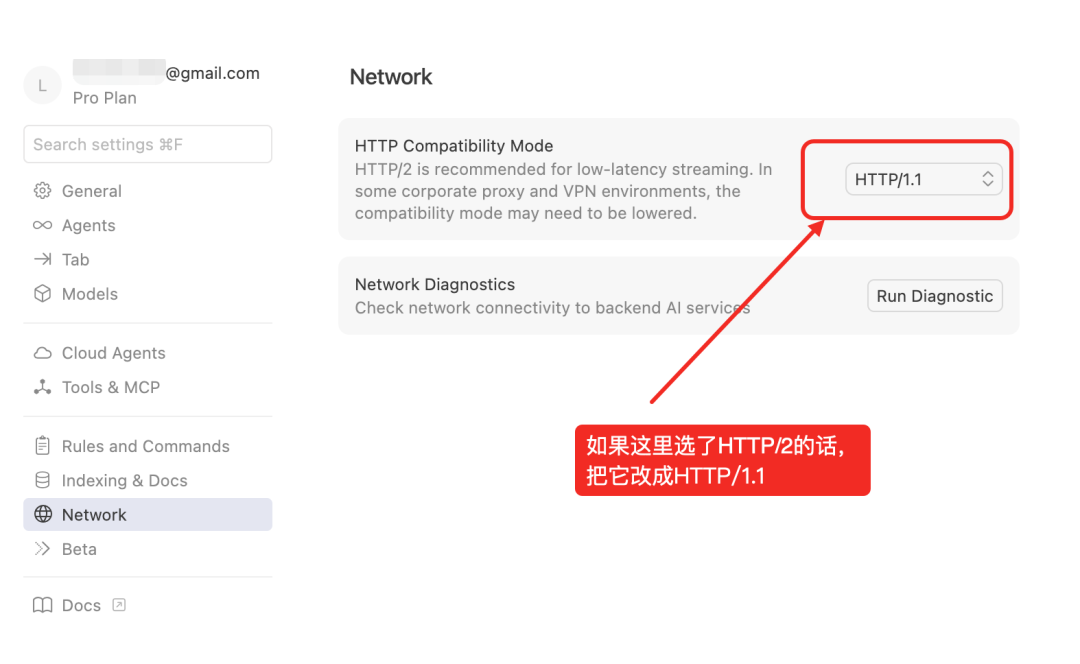
一、Curosr莫名其妙地作了一次妖,主动检测我的IP(应该还蛮严格的)识别出来我是使用了代理,便限制我使用GPT和Claude系列的模型,只能选择Auto模式或者Composer 1模型,周末在家折腾业务的复杂数据分析时,正需要找GPT-5.1和Opus 4.5来帮我解决复杂问题的时候掉链子了,给我气坏了,只能将就着用Auto模式,磕磕绊绊地来回沟通讨论,也算是把活干了,但是真的给我恶心坏了,一会儿后面展开聊聊Cursor这样的厂商的核心竞争力(仅代表我个人的观点)。关于如何解决Cursor识别IP归属地区后限制部分高级模型的使用,后面我在X上看到有推友分享了一个方法,那就是进入Curosr Settings -> Network -> HTTP Compatibility Mode,把它从HTTP/2修改为HTTP/1.1,然后确保自己的代理出口IP是美国/日本/新加坡等不受OpenAI、Anthropic、Google等等这些AI厂商提供服务的地区限制的国家/地区的IP即可。
二、使用Cursor这么久我一直都只是订阅了最基础的Pro一档的套餐,虽然也开启了On-Demand这个选项,实际上一直也没有真的产生消耗,这个选项的意思是,如果我这个月的用量已经超过了Cursor Pro的20美金的总用量,会开始从这个我设定的On-Demand的限制中开始计费,直到消耗完毕后Curosr会停止服务,举例说明:如果我在12月20日已经把Cursor Pro中自带的20美金的用量花没了(实际上还是很耐用的,反正我基本上没有遇到过花超的情况,Cursor还是蛮慷慨的),假设我给我自己的账号设置的每月的On-Demand金额为10美金,那么从12月21日往后的调用,计费就从这个On-Demand账户中的10美金来进行预扣,下个月账单中会体现出来这部分实际消耗的费用。叨叨叨说了这么多,实际上我从来没有在Cursor这儿感受到过限额或者费用高昂的问题,那么为啥退了呢?这是因为OpenAI发布GPT-5.2模型的当天,Cursor便上线了该模型的能力,向所有用户开放使用(我不确定是不是仅限Cursor Pro及以上用户),我自己图新鲜也尝试了一把,体验的结果是速度真慢(我平日的编码需求并没有那么复杂,对模型能力的需求可能并没有那么高),我有点不信邪以为是网络的额问题,连续试了四五次请求,都超级慢,最终我选择放弃指定GPT-5.2模型,切换回Auto模式了,继续执行了几次请求,依然速度慢到令人发指。当天我就把工作切换到了Antigravity上了,而Antigravity不负重望地出货很快,且当时我是免费在用,新发布的Gemini 3 Pro模型更是能力上升一个大台阶,比在Android Studio中调用那个Gemini Code Assistant只能访问Gemini 2.5 Pro模型更是不可同日而语。
就这么的,Cursor Pro从正室被降成了丫鬟,Antigravity刚进门就成正室了,这两周每天都在高密度地帮我输出Flutter代码和数据分析任务的计划和指令,确实值得20美金的这个价格,而且出活效率是真的高,比Claude Code Max、GLM Coding Pro、Cursor Pro出活都快,稳定性也很不错。从出活速度上唯一可以跟Antigravity对比的,可能只有JetBrains AI Pro了,但是JetBrains AI Pro的模型能力相对会有些限制(北欧公司一般都比较稳健,一点也不卷,模型和产品迭代速度都相对较慢,不过可靠是真可靠啊,基本上没有遇到过失败的问题。他们自己家的Junie这个Code Agent也在持续迭代更新中,有兴趣可以了解一下)。
时间来到了周五下午,原本计划当天要完成的礼物动画播放队列的功能应该在周五完成的,但是因为周五晚上团队有些其他安排,下班比往常早了不少,晚上聚完餐回到公司,继续折腾了半个小时,Antigravity一直在几个社区开源的礼物动画播放器与当前项目的版本兼容性上绕来绕去,每次调试编译都需要不少的时间,最终问题未能解决,便去地铁站等同一天下班很晚的老婆一起回了家。
到家后时间不算很晚,还是很不爽,本想着继续肝一肝,看看今天晚上能不能搞定这货,最终还是败下阵来,简直毫无进展,Antigravity一直在来回打转。无奈之下,趁着家里网络好,把那个复杂的数据分析任务,先让Antigravity启动了(公司网络有限速,对于需要下载外部资源的数据分析来说很不友好),洗洗便睡了。
周六一早起床,吃过早饭,继续肝,昨夜Antigravity守着数据分析的任务已经完成的大差不差了,先放着让它把剩下的不到20%的分析继续执行着,我们继续改Bug。谁知这货还是来回绕啊绕,想着每次它都自行分析后就开始干活这个套路过于浪费时间,我便把编译错误日志,先给了ChatGPT,未曾想ChatGPT一语中的,直接给出了当前项目中的问题,一句话就点破了问题所在,并且给出了一个在社区开源项目首页的README中就明确注明了的方案(一句未加粗的普通说明,但是很明确)。手动修改后,再次编译,问题得到解决。而此前Antigravity一直在试图把社区的开源项目clone到本地,然后自行分析并做出修改和调整来解决这个编译时版本不兼容的问题,而这个开源项目的链接地址它早都访问过很多遍了。看来社区中大家的一个普遍共识:GPT擅长复杂任务的分析、Claude擅长编码任务的执行(我想Gemini也差不多),属实不欺我也,GPT的脑子就是好使,Gemini的手是真快。
在ChatGPT通过对话框的方式帮我解决了编译问题后,我们就继续开始业务逻辑的推进了,在调试代码和测试功能的过程中,Antigravity又一次把我引入了死角,在礼物动画出队开始下载资源和播放的时候,会出现卡死整个Flutter主进程的问题,我尝试着读了一遍它写的代码,愣是没有找出来问题所在,一遍又一遍地跟它来回讨论和互动。期间二娃跟他妈妈要去上乒乓球课,原本我也一起陪同,还能跟老婆在乒乒球馆里一起打会儿球(老婆是个乒乓球迷),但是这个问题不解决实在心痒难耐,便拒绝了一同前往的邀请。折腾了一个整个上午,卡在了这个问题上,娃儿跟老婆回来吃午饭了,便跟着一起吃了午饭。
午饭后,继续磨啊磨,先是梳理了一下代码逻辑,整理了一下代码注释,再次重新出发,不过Antigravity还是没能很好的解决问题。这个时候我又一次想起了GPT 5.2,打开VS Code,唤起Codex,选择了一个GPT-5.1-Codex-Max模型,把我当前正在做的事情以及关联的几处代码跟它说明了一下,然后再把当下遇到的问题给它大概说了一下,让它帮我找一下问题可能在哪儿(请注意,我连日志都没有给它,因为不是错误日志,是主线程被Hang住了,没有什么特别有价值的日志,这是程序执行逻辑错误导致的)。
未曾想这个从未登堂入室的二房(Codex),花了不到1分钟就把问题分析清楚了,指出了可能导致问题的一处代码,并给出了修改意见,执行编码修改后,再次运行问题彻底得到解决。就这么滴,被Antigravity折磨了近3个小时的我,被Codex用了3分钟解救了。这个时候,老婆已经带着大娃和二娃去公园玩冰去了,还给我发来了公园里钓友们在冰面上钓得鲫鱼的照片。

既然问题已经得到解决了,那就继续让Codex帮我整体Review一下当前的这个代码设计和实现,它很是中肯地对Antigravity的设计和实现提了4处要紧和6处不要紧的优化和修改建议,一一执行后,换上衣服出门跑步去了。进入12月份后,家中事情有些多,平日跑量骤减,得追追进度了。
跑步的路上,一直在想这个问题「AI大浪潮时代里,像Curosr、OpenRouter这样的完全依赖大模型产商的公司会有生存空间和未来吗?」
5年前的我,可能不会去想这个问题,10年前的我可能会直接回答「它们的生存空间会很小,逐渐在时代的浪潮中消失」,现在的我,在一路跑步的过程中,不断地在问这个问题,零零散散的,有了下面的一些思考,记录一下,也分享给大家:
先说结论,Curosr和OpenRouter这样的厂商会有很大的生存空间,未来可以很好,虽然不一定能像OpenAI这样的时代弄潮儿一般,但也肯定会是一个10亿~100亿美金体量的公司;
这两家公司的商业模型,有相似之处,也有不同之处,我们一一来展开。
先说Cursor,这是一个核心用户界面以基于VS Code(微软旗下的一款开源代码编辑器工具)的商业化高度集成AI Code Agent的IDE,收入来源于个人用户和企业用户的订阅费和模型用量调用费。
从产品交付上来拆解,Cursor提供两个集成的服务:集成了AI Code Agent的IDE和大模型调用能力,实际上我们也正是为这两个能力进行付费的,与此类似的产品有Claude Code,以及其他一众产品,我们在此不一一列举了。
这一类型的产品核心能力就两个,一是AI Code Agent产品的能力,例如:计划和任务的拆解、合理的工具调用推理、提供给用户的交互界面和易用性,Cursor作为AI代码工具的吃螃蟹者,一直都走在行业的前面,后面众多的跟随者无一不是采用了与其产品基本类似的方式提供产品服务,从用户界面和产品交互,成为了行业默认的标准,而这些看似只是一些工程化的工作,背后实际上有着大量的思考、论证、迭代、优化的工作,最终呈现给到用户们的是当下的产品形态,我们只需要在对话框中描述我们的具体需求,或者选中某一段代码发送给输入框,然后继续在输入框内输入指令或需求,又或者是在代码编写的过程中通过Tab键的自动补全提前帮用户把将要完成的代码一次性补全输出。
看似简单的三个核心功能,实则背后有着大量的工程优化,单纯从需求分析和工具自主选择上,我在使用Cursor做复杂数据分析的过程中基本上不需要自己来给出任何意见,它自己便能做成合理的推理并选择最终使用的工具或者实现方式来达成目的,而Antigravity便没有那么聪明,需要明确指明让其通过ipynb这样的方式来做数据分析,它才会这么干,否则它就会选择一次性的python脚本分析来完成,哪怕你在需求描述中都跟它说明了我们需要持续针对数据分析的结果一步步地深入做分析。此外,Cursor最新版本在Agent自主执行任务前,主动向用户提问,并且通过可视化的交互方式来与用户达成进一步需求确认的优化(用户可以通过勾选Cursor给出的选项,甚至可以在勾选选项后再次给出补充信息),然后再次确认后开始执行的优化,比市面上绝大部分纯文本或者列表式输出要点,让用户再次通过文本输入的方式来确认的交互方式就提效非常多,且可以持续多次迭代确认需求细节,无疑对于最终Agent执行的效果有着非常大的提升。
其次是其背后对接的大模型厂商的多样性,对于终端用户来说去对接那么多的大模型厂商,且不说模型厂商的接口是否会存在一定的差异(虽然OpenAI的先发优势,让全行业的厂商最终提供的API接口基本上都是OpenAI Compatibility的),就是光开通这些模型厂商的账号维护账单都是一个非常让人头疼的事儿,更不说厂商们发布产品的时间周期越来越短,模型的能力各种各样,用户们要如何及时地去对接调试和评估不同厂商不同模型的能力都是个非常需要投入时间和精力的工程(且不论是不是每个用户都有这个能力去做好这两件事儿)。
一个很小的例子,就是Antigravity一直不能很好地遵守全局GEMINI.md文件中的规范,例如我明确要求其在思考推理、与我沟通、制定计划和输出内容时限制必须使用中文简体,但是其总是会在各个环节出现忘了这茬儿,需要多次手动重复提醒,而Cursor在遵循一整个rules目录下不同的规则文件中声明的规则时依然可以长期保持一致性,而不出现错漏。乃至我在X上都看到不少跟我一样遇到类似问题的人在探索和分析如何让Antigravity一直输出中文的优化方案😂,这就是Cursor团队在背后做了大量工程化工作的结果,包括Antigravity直到现在也没个后台和好的入口可以查询你当前用量,而Cursor在账单和用量上已经做得非常到位,且都是实时更新。当然现在Antigravity这个慷慨的用量额度,大体上绝大部分人不需要去关注到这部分内容。
所以Cursor不论其在产品能力上的创新和先进性,其在工程和生产流程上做了众多的脏活和累活,最终把一个稳定可靠且创新的产品交付到了用户的手上,虽然其基座模型主要还是依赖OpenAI、Anthropic、Google这样的大厂,也有Composer 1这样的自研模型(不确定是否有依赖其他开源大模型),看上去核心大模型能力依托于其他基座厂商,但是用户其实想要的就是稳定可靠好用的产品,仅此而已,这个套用到任何行业任何产品,都是适用的。好比我们看中国的首富,总是卖水的公司的老板一般,中国人都会烧开水喝,可是农夫山泉愣是能创造这么大的商业价值(这还不是那些可能有泡沫的行业哦)。
再来聊聊OpenRouter,在国内有一家跟OpenRouter的商业模式非常接近的公司名字叫硅基流动(SiliconFlow),核心商业模式就是AI大模型厂商API Token的批发和零售商,他们从OpenAI、Anthropic、Google、阿里、月之暗面、MiniMax、智谱等等厂商那儿批量采购大量的API Token,然后再通过其平台进行转售,终端用户在调用其提供的不同厂商的模型时,只需要修改接口中传入的模型名(以其平台上模型名为准)即可实现一键切换各大厂商的模型调用,所有厂商之间接口的差异,都由他们居间搞定了(看上去跟Cursor一键切换不同的模型有着异曲同工之妙,当然他们之间是否有合作也未尝可知)。简单可靠,开箱即用,此为其一。
当然当OpenRouter和硅基流动等API Token分发商们足够成熟后,完全也可以自行部署和优化当下社区里的开源模型,DeepSeek、Qwen、Kimi、MiniMax都会是很好的可商业化部署的大模型,而对于终端用户来说,这也是一种非常灵活的能力,可以在众多开源和商业闭源模型中去遴选适合自己业务场景的模型能力,在能力和成本之间找到平衡,把自己的能力和精力更多的放在垂直领域下业务的打磨上,而不是耗费大量的时间和精力去做基座模型的技术对接和适配(边际成本太高,毫无规模效应)。生态丰富,丰俭由人,平台借由规模效应摊低用户接入的边际成本,此为其二。
前些日子看到媒体在报道各大厂商的模型Token的调用量时,赫然在列的一个第三方公开数据便是OpenRouter每日API的调用量,掌握这个数据,显然就掌握了子弹打向了何处(考虑到隐私问题,哪怕只是知道了Token费用流向了哪些厂商,对于商业社会中的很多决策都能造成影响,更不论接口调用的实际应用情况了,我们姑且认为他们都不会这么做,我也没有仔细研究过他们的隐私政策和用户协议)。厂商们甚至都会反过来找OpenRouter要数据反馈,毕竟他们每家只有自己家模型调用量的数据,对于其他家的不同模型的实际调用量和受欢迎程度也不了解不是,说得再阴谋论一些,哪天会不会刷OpenRouter的榜也不好说😂,这不就是大众点评的路数嘛。汇众家之所长,积累了大量的实际生产环境的调用数据,也许是一个潜在的数据金矿,此为其三。
最后,前一阵子收到一封OpenRouter发的邮件,内容大体是他们支持了用户调用流量的旁路流量的复制和重放,这对于复杂业务和工业级应用简直就是利器啊,在当下Agent和LLM提示词工程普遍还存在开盲盒的情况下,Agent和LLM工程过程的可观测性和结果的可评估性,显得尤为重要。这里我们甚至可以畅享未来他们会有更多工程上的创新,包括一些高度自定义的负载均衡器之类的能力的推出等等。

以上是基于产品特性和行业生态,对于这两家公司的核心商业竞争力的一些浅薄的思考,其实除此之外,我还想单独针对一些抛开产品力之外的一些合规问题再展开一下。
先说可得性,Cursor和OpenRouter都解决了绝大部分中国大陆(以及其他服务区域受限的国家和地区)开发者和用户们会遇到的限制服务使用的问题。Cursor和OpenRouter只需要一张支持Visa或Mastercard结算的信用卡,便可开通服务直接使用。如果我们要用ChatGPT、Claude的客户端,或者直接调用OpenAI和Anthropic的API,付款的银行卡风控极度严格,中国大陆和中国香港发行的Visa和Mastercard信用卡都会被拒付,费老大劲折腾找了一张虚拟卡,也保不齐下个月就拒付了。更有甚者因为使用代理导致IP共享,刚刚开通Pro的账号,便触发了这些厂商内部的风控策略,账号都扬了(社交媒体上,每天都充斥着大量的这些讨论)。而使用这两家公司的产品,便完全不用太担心这个问题,首先他们不会扬你的账号(只要你不是很过分,而且因为本就是付费服务,咱也过分不到哪儿去,那几家大厂风控策略严格,是因为免费用量被黑灰产薅羊毛薅的他们必须对抗才有的策略),虽然Cursor最近升级后限制大陆地区用户使用特定模型的事情也有点那个味道了(可能是监管有压力,who knows),单但是整体上还是很容易解决的。
再说接入成本,对于任何一个渴望稳定和效率的企业或团队,哪怕是有同样需求的个人来说,使用Cursor和OpenRouter都是一个能极大降低接入成本和各种其他摩擦成本的优秀的选择。举个例子,公司要想评估各家不同模型厂商提供的模型能力,如果我们一家家地去谈合作,要一些测试Token,测试通过后再签合同,这一套下来,但凡经历过这些流程的人都知道,等流程走完,这个模型都已经进化一两个版本了。而且不同厂商的结算方式,账单日,合同签订等等都是一堆的跟实际产品力无关的具体需要做的合规动作,而选择直接使用Cursor和OpenRouter,我们便借助了这两家优秀的公司帮我们把大量的这些流程性的支出给摊薄了,而他们则可以在这个优化了全社会或者全行业链路和效率的环节上获得属于他们的收入和利润,这就是商业的本质,被别人需要,解决了商业世界中某个流通环节的成本或效率优化,那么你便可以获得该环节的价值溢出,继而取得收入和利润。如果杠杆足够大,那么利益也就被无限放大了,这就是农夫山泉看上去只是做了大自然的搬运工,但是却可以创造这么大商业价值的核心原因。
跑了近100分钟,下午3点触发,4点37回到家,跑了15.5公里,回到家的时候,娃儿们跟着老婆已经回来了,二娃一会儿还要去画画,我也准备洗完澡,一会儿再送他去上课了(这一天可算不闹心了,要是这问题没解决,我还得继续后面折腾😮💨)。
回到文章的标题,这次为啥又是Codex救我狗命呢?实际上我使用Codex来帮我写代码的时间很少,重度使用的排序应该是:Cursor (70%,最近换成了Antigravity),Claude Code(20%,最近停止订阅了,因为它的Pro用量低到无法干活,而Claude Skills完全可以用Antigravity依葫芦画瓢实现),JetBrains AI(10%,偶尔补充使用,年订阅费用不算高,老早就买了,不用白不用了),Codex(偶尔尝鲜,或者帮我临时解决某个问题)。Codex时不时地能帮我解决让我头疼的问题确实有点出人意料,但是它能一直作为一个备选项存在,实则主要原因是因为它是ChatGPT Plus用户的附赠权益,而作为头部AI厂商的OpenAI的拳头产品的ChatGPT一直都是一个很好的产品,我相信在未来的两年内,我应该都不会主动取消它的订阅,这样就让我总有机会用Codex来帮我解决一些其他AI Code Agent造成的或者未能解决的问题,而Claude就一直因为它的风控以及用量问题无法扶正导致很多时候也许它有能力,但是我用不上它,这样OpenAI的产品体系在我这人就形成了一个正反馈循环,而Anthropic的就相反了,如果不是他们家产品能力的创新足够打动我,我是很难想起来要用他们家的产品的。从这个角度来看,一个产品只要能持续留在用户的手机上或者保持在用户的订阅列表中,没有被用户从账单中清除掉,那就留有足够的机会,保持在场,就有机会持续进步。于OpenAI的Codex如此,于我们更是如此。但凡有机会,一定要保持在场,持续在场,那就持续有机会。
就写到这里吧,少年宫的走廊上暖气不足,伸在外面打字的双手已经拿不稳手机了,冻死我了🥲,喝点热茶先。
下周要准备写年度总结了,年末见,朋友们。今日冬至,不知各位是否有吃饺子或是汤圆。(今天何老师科普了一下,冬至时节,全国各地的时令吃食差异,北边吃饺子为主,华中和华中部分地区吃汤圆为主,云贵川地区喝羊肉汤,岭南三地吃鸡为😄)

原文链接: 微信公众号
原文发布于:2025年12月21日 18:19